RESEARCH
Blind Source Separation
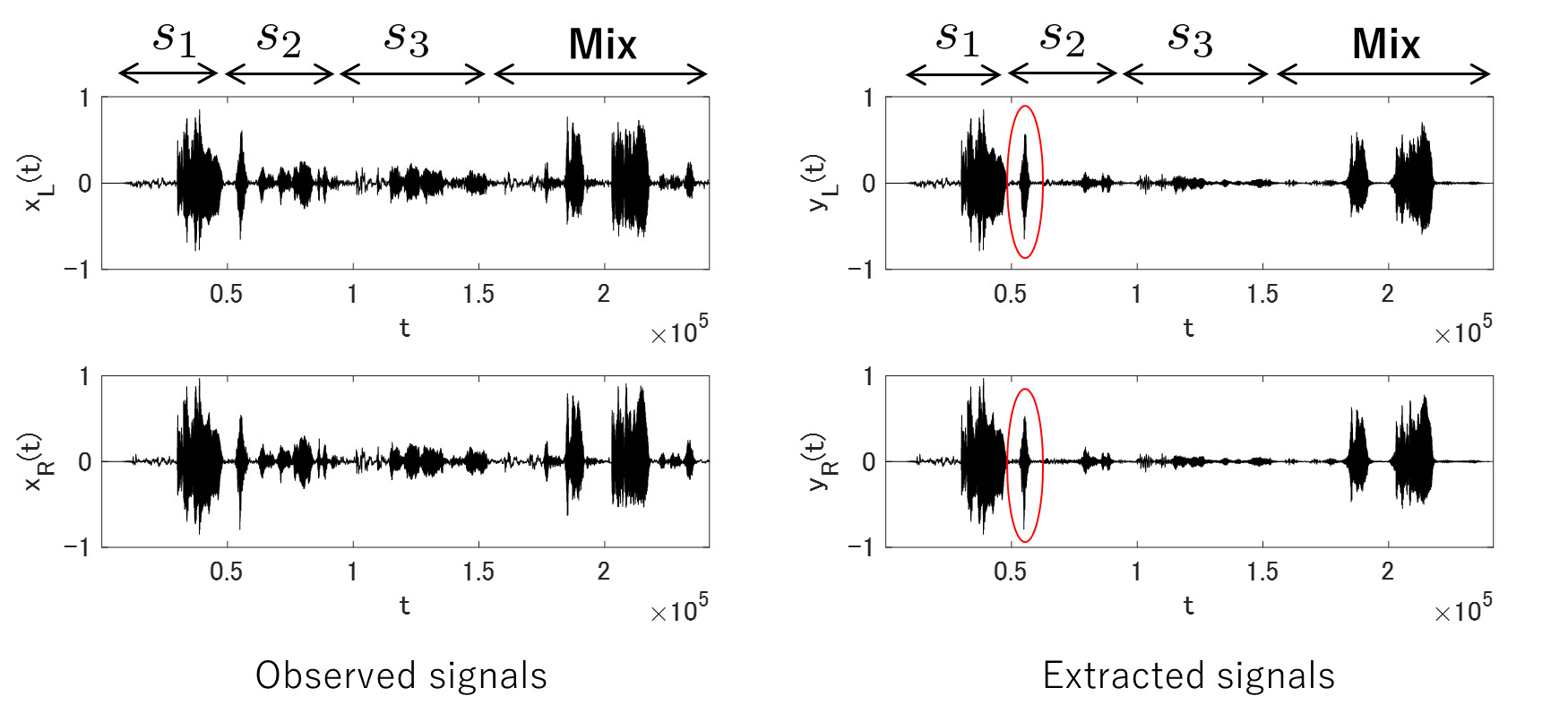
When an observed signal includes multiple sound source signals, the proposed method separates it into respective sound source signals.
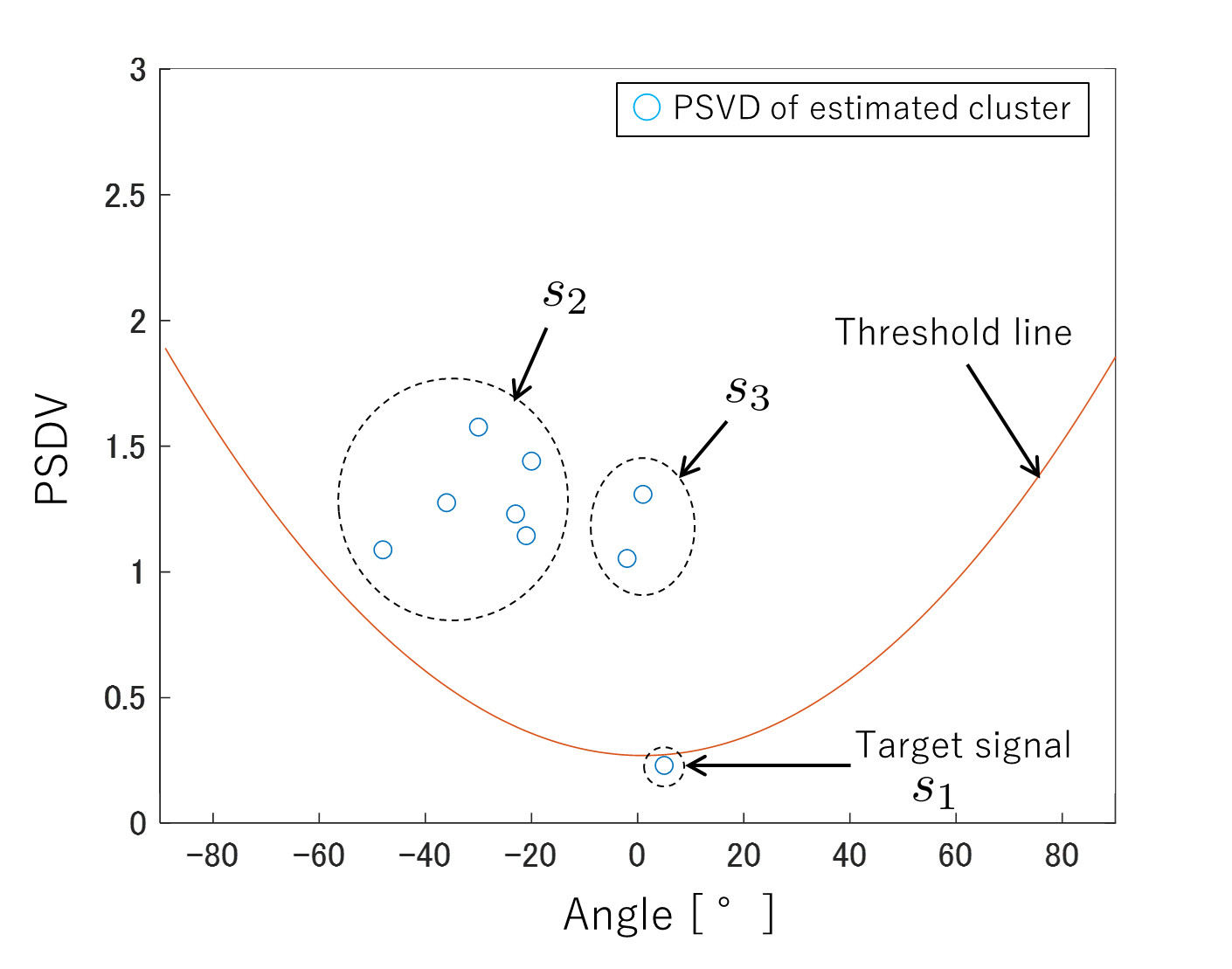
The proposed method uses single voice activity segments which includes only single sound source.
Using the single voice activity segments, we easily get clusters for each sound source.
After making these clusters, we can effectively separate sound source spectrum.
The proposed method evaluates the separated sound sources and suppresses distant sound sources.
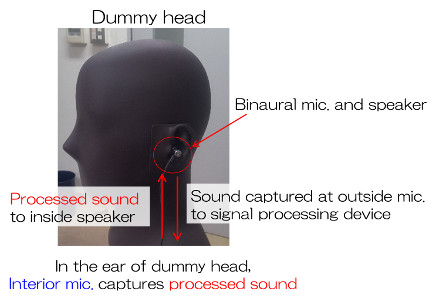
We investigate a real-time blind souece separation system used in hearable device,
Utterance Training Device
We are investigating about an utterance training device for hearing-impaired person.
We have developed SANON which extracts "s" sounds.
SANON have been tested in an utterance training school for hearing-impaired person.
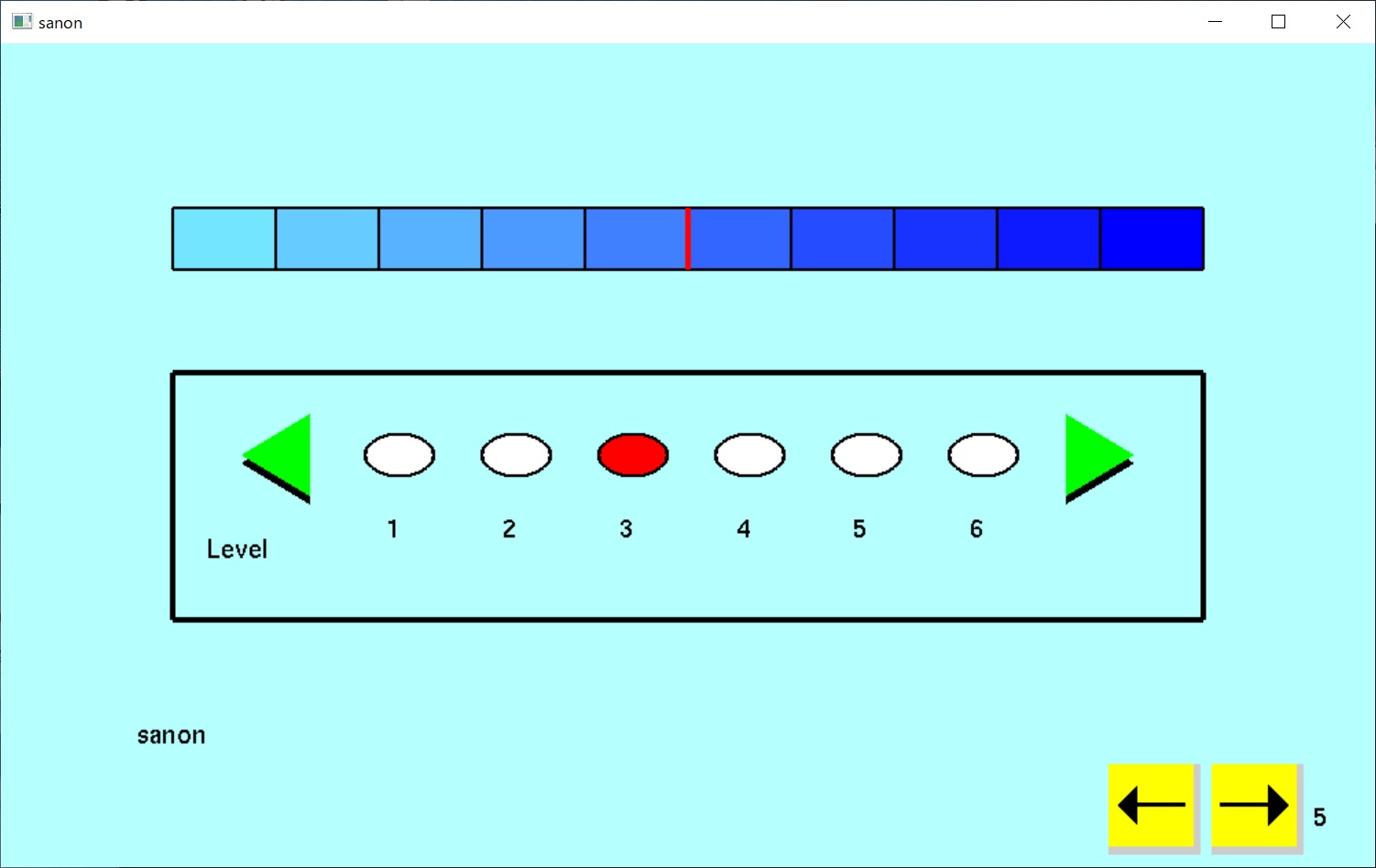
Image-to-Sound Transformation
This study is about an embedded system where an image is embedded in a speech signal. As well known, a spectral amplitude is more important to get an intelligibility of a speech signal than a spectral phase. But, in long time Fourier transform, the spectral phase plays a more important role to get the intelligibility. Based on this nature, we use an image signal as the spectral amplitude, and a speech signal as the spectral phase. Taking the inverse Forier transform of the above integrated signal, we have a speech signal emmbedding the image. We try to implement this technique on FPGA, and evaluate its capability in a real environment.
Hearable Devices
Recently, many researchers focus on hearable devices which is one of wearable devices.
The hearable devices are devices like hearing aids or earphones.
Its functions are music listening, speech communications, automatic translation, bio-information acquisition, personal identification, etc.
The aim of our research is to implement our noise suppression, speech separation, and other speech signal processing techniques on the hearable devices,
and develop next generation hearable devices.
Zero-Phase Signal Processing
Zero-phase signal is defined as the inverse Fourier transform of spectral amplitude.
Zero-phase signals obtained from wide-band noise signals have large values only around the origin of the zero-phase time axis.
On the other hand, a zero-phase signal of a voiced speech signal has periodicity.
We developed a replacement method of the zero-phase signal to suppress noise signal.
This method can suppress stationary noise and impulsive noise with the same procedure.
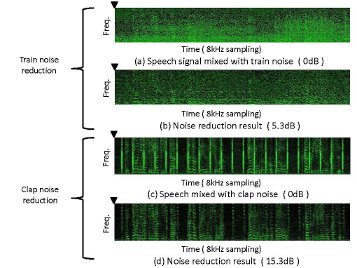
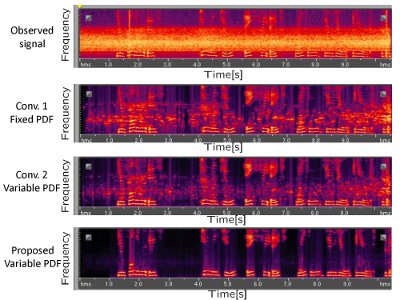
Noise Suppression Using MAP Estimation with Variable Speech Distribution
We investigate a noise suppression method using MAP (maximum a posteriori) estimation.
Based on speech spectral distribution model, typically Gaussian distribution, the MAP estimation extracts speech spectral amplitude from an observed noisy spectrum.
The proposed method introduced a variable speech spectral distribution model into the MAP estimation,
and achieved high-quality speech extraction.
Noise Suppression Based on Linear Prediction
We utilize a linear predictor with low computation load to suppress a noise from a noisy speech. We can implement this method on a DSP (Digital Signal Processor) or FPGA. Although this method is established to suppress an acoustical noise, we also investigate about noise suppression in radio wave. Specifically, we suppress a radio wave generated from an electric device which is an interference of a FM radio wave.