
経済データ処理実習 第9講 「ケインズ型消費関数は正しい?」
|
※今回のみ2ページ目があるので注意!
| Ⅰ.実証研究と回帰分析 |
| Ⅱ.最小2乗法の説明 |
| Ⅲ.まず、散布図で(以降2ページ目へ) |
| Ⅳ.回帰分析-分析ツール- |
| ※練習問題 |
今回および次回では,「回帰分析」というデータ処理を学びます.これは,経済学における実証研究で最もよく使われている手法です.
まず,実証研究が,どんなものなのかを一言でまとめると,それは,理論モデルや経験的な事実から得られる仮説を
データによって立証する(というと大げさですが)分析手法です.
例えば,
「都市よりも農村地域での方が,無駄な公共事業が多い」
とか,
「最近の若者は活字を読まない」
など,テレビ番組の中などでもよく耳にする話です.
また,マクロ経済学の中で登場した「ケインズ型消費関数」というのも,「所得が増えれば消費も増える」という,ミクロ経済学での消費者の行動モデルをベースにしているものです.
こういったことが「ある程度もっともらしいのかどうか」を確かめる,というのが実証研究です.(「真実かどうか」を確かめている訳ではない!)
公共事業の例で言えば,都道府県別の第1次産業の比率と,公共施設の利用率(こんなデータ実在しませんが)のデータを使って,散布図を作ってみると下図のようになったとしましょう.すると,先の発言は「ある程度の根拠のあるもの」と立証されるわけです.
|
逆に,活字離れの例では,読書時間についてのアンケートを行い,回答者の年齢と読書時間のデータから,下の散布図のようになったとすると,先の発言は,それを言った人の個人的な経験から得られただけのものであって,「大した根拠の無いもの」と言うことができます.
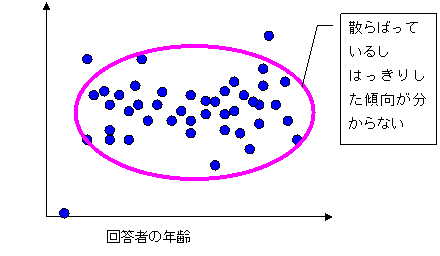 |
このような,ある仮説を立証するために,「データから傾向を読む」というのが回帰分析です.(簡単に言い過ぎてますが)
では,この回帰分析,どのようなことをするのかを簡単に説明します.色々な方法があるのですが,一番メジャーなのが「最小2乗法」です.これをケインズ型消費関数の例で説明します.テキストなどの中でケインズ型消費関数は次式で表されます.
C0は独立(基礎)消費,cは限界消費性向でしたね.図で描くとこんな感じです.
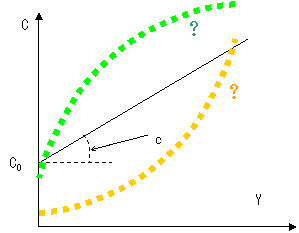
テストなどでは,C0やcに適当な数値を入れていましたが,実際にこれらがどれくらいの値なのかは分かりませんし,そもそも実際の傾向が直線で表されるのかさえも分かりません.(オレンジや緑の線のような傾向かもしれません.)
一応,ここでは上式のような関係を想定します.このとき,所得や消費のデータがあれば,C0やcを推定できます.
例えば,所得が100のとき消費が120,所得が200のとき消費が180,というデータが得られていれば,
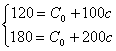 |
という連立方程式からC0=60,c=0.6という値を導出できます.
ただし,算数と違うのはたった2つのデータから導出された値が本当に全体的な傾向を表せるものかどうかが分からないことです.もっと多くのデータを使って所得と消費の関係を散布図にしてみると下図のようだったとしたら,これでは明らかに誤った推計です.
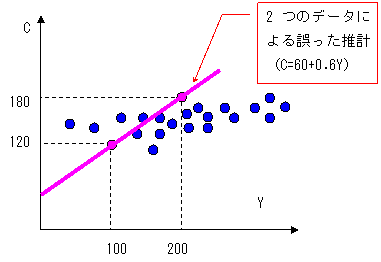 |
そこで,より正確な推計をする方法が必要です.それが,最小2乗法です.(以降,詳しい説明は計量経済学の授業で)
最小2乗法とは,「残差の2乗和が最小になるようにデータから近似的な傾向を求める」方法です.
一般的な式で,次式のような関係を想定します.
ここで,Yを被説明変数,Xを説明変数,eを残差と言います.ケインズ型消費関数で言えば,Yが消費に,Xが所得に該当します.iは1番目からn番目まであるデータの任意の番目を表します.図で表すと下図のような感じです.
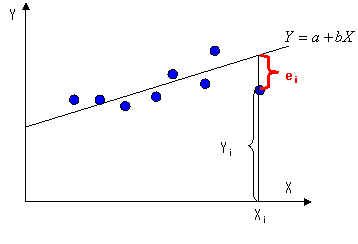 |
消費に限らず,実際の経済主体の行動はランダム性が高いため,近似的な傾向(実線)と実際のデータでのYとXの関係には必ず残差が生まれます.それはプラスであったりマイナスであったりするわけですが,最小2乗法はどのデータに対しても最も近くなっているような近似線を引くのです.