経済データ処理実習 第10講 「ちょっと進んだ回帰分析」
|
| Ⅰ.回帰分析について(復習) | |
| Ⅱ.重回帰分析(他変数を用いた回帰分析) | ※練習問題 |
| Ⅲ.多重共線性の問題と回避方法 | ※練習問題 |
Ⅰ.回帰分析について(復習)
前回やった回帰分析について,簡単に復習しておきましょう.
まず,理論モデルや経験的な事実から得られる仮説をデータによって立証するという実証研究の中で最もよく用いられる分析手法,それが回帰分析でした.前回やったことで言うと,
![]()
という数式で表されるケインズ型消費関数のように,「所得と消費の関係は,統計データで見てこのような線形の関係にあるのだろうか?」ということを確かめてみました.
また,回帰分析の中で最もメジャーな方法が最小2乗法です.
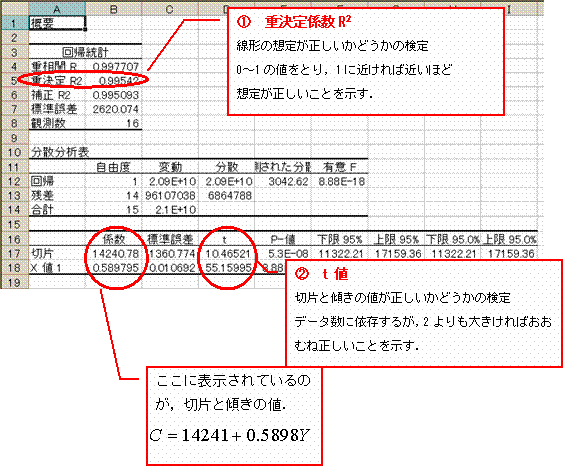
家計調査のデータを使って,消費関数を推計すると,次のような結果を得ました.重決定係数,t値ともに有意な水準ですので,この推計は概ね確かなものです.
散布図を使って作図してみると,
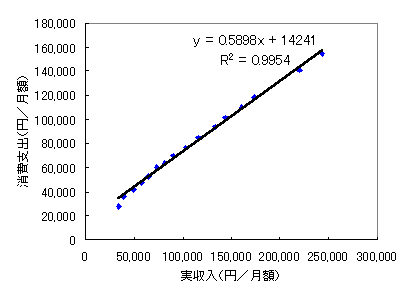
このように,所得と消費の関係は,ケインズ型消費関数が示すような、ほとんど線形であることが分かります.
Ⅱ.重回帰分析(他変数を用いた回帰分析)
さて,前回やったのは,
![]()
という数式の推計だったわけですが,この式は被説明変数が1つ(この場合は消費),説明変数が1つ(この場合は所得)の回帰分析でした.こういうやり方を単回帰と呼びます.それに対して,1つの被説明変数を複数の説明変数で推計する方法を重回帰と呼びます.
例えば,
実際の人々の消費を考えると同じ月収40万円でも,Aさんの家族は幼稚園に通っている幼児が1人なのに対して,Bさんの家族は高校生と中学生の子供がいたとします.
両家族の消費額は,Bさん家族がよほどの節約家でない限り普通は違ってくるはずです.
また,夫婦共働きで月収40万円のCさん家族は,Aさんと同じく幼稚園に通っている子が1人であったとしても,Aさん家族とは消費額が違ってくるかもしれません.(Aさん家族の奥さんは専業主婦だとします) なぜなら,やはり共働きは忙しく外食する場合が多いかもしれないと考えられるからです.
このように,人々の消費には,単に所得だけではなく,家族構成なども影響を与えていると考えられるわけです.
そこで,次のような仮説を立てます.
![]()
つまり,「家族の消費は,所得だけでなく,家族の人数(M)や奥さんが働いているかどうか(J)にも依存しているだろう」という仮説です.同じ意味ですが,もう少し「計量経済学」的に書くと,
![]()
となります.ここで,iは各階級,αが切片,β1~β3が各説明変数の係数です.ここで注意が必要なのは,このような消費関数のαは,既にケインズ型消費関数で言う基礎消費ではないということです.
では,前回と同じく「家計調査.xls」のデータを使って重回帰分析をやってみましょう.
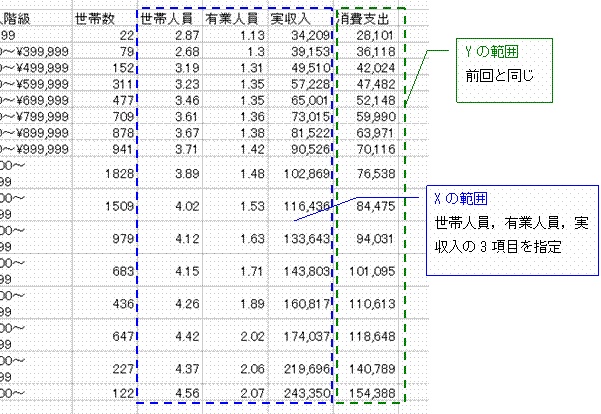
家計調査の上では,家族の人数(M)に当たるのが「世帯人員」,奥さんが働いているかどうか(J)に当たるのが「有業人員」と考えてください.※有業人員が2を超えている場合は,仕事をしている未婚の子供が含まれています.
前回やったように,「ツール」→「分析ツール」→「回帰分析」で回帰分析ツールを起動します.「Yの範囲」と「Xの範囲」は,以下のように設定します.
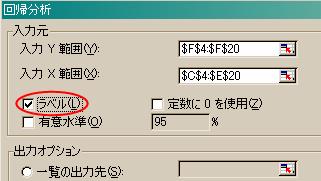
また,このように先頭行に項目名を含めて範囲を指定した場合は,以下のように,「ラベル」部分にチェックを入れておきます.
出てきた結果は,このようになります.ここで注目して欲しいのは,「有業人員」のt値が2以下なので,「有業人員」は説明変数として有意ではない,ということです.

※練習問題
1980年,1990年,2000年についても「消費支出」を,「世帯人員」,「有業人員」,「実収入」で重回帰しなさい.
Ⅲ.多重共線性の問題とその回避方法
①多重共線性の問題
上で見たように,「有業人員」は有意ではないということですが,これは最初に考えていた仮説が成り立っていないことを示すのでしょうか?
実はそうとも言い切れないのです.
これは重回帰分析に特有の問題によるものなのです.それが,多重共線性の問題です.
単純に考えてみてください.
「共働き家族ほど子供の数が多い」というのは,あまり納得的ではありませんが,「共働き家族ほど実収入が多い」と言われれば,そうかなぁと思います.なぜなら,家計調査に出てきている「実収入」とは,旦那さんと奥さんの稼ぎの合計額ですから.
この,「実収入」と「有業人員」とのように,「説明変数の間に関連がある場合,回帰に歪みが入りt値が過小に算出されてしまう」という問題を,多重共線性と言います.
この問題が発生した場合,関連のある説明変数のどちらかを回帰分析の際に使わないようにしなければいけません.
②多重共線性の検出
では,回帰分析を行う前に,多重共線性を起こしそうな説明変数同士の関連をどうやって見つけるのでしょうか?
まずは,今回の「実収入」と「有業人員」のように,説明変数として使おうとしているデータ同士が関連していないかを直感的に考えるのが良いでしょう.しかし,それではあまりにもあいまいだし,見つけ出しにくい場合もあります.そのような時に使いやすいのが,VIF(Variance Inflation Factor:分散拡大要因)という尺度です.定義式は以下で表されます.

ここで,![]() は,変数aとbとの間の分散拡大要因,
は,変数aとbとの間の分散拡大要因,![]() は,変数aとbとの間の相関係数,
は,変数aとbとの間の相関係数,![]() は,相関係数の2乗を表します.
は,相関係数の2乗を表します.
このように定義されたVIFが10以上になるような説明変数同士を同時に使うと,多重共線性を起こす可能性がある,と一般的に考えられています.
とりあえず,やってみましょう.このためには,「相関係数の計算」と「VIFの計算」という2ステップが必要です.
(第1ステップ)相関係数の計算
相関係数は,回帰分析と同じく分析ツールを使って計算できます.「ツール」→「分析ツール」→「相関」と進みます.

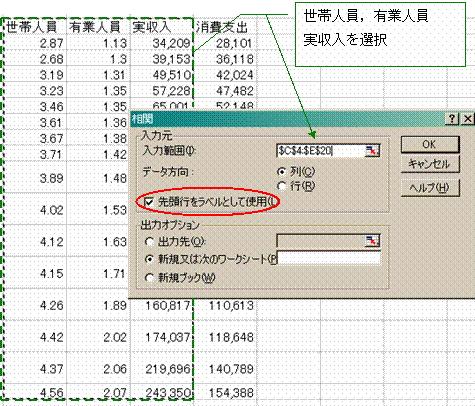
「OK」ボタンを押すと,次のような結果が出てきます.(色は付いていません)
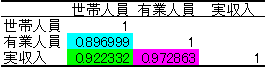
この表は,
世帯人員-有業人員の相関係数:0.896999
世帯人員-実収入の相関係数:0.922332
有業人員-実収入の相関係数:0.972863
という3つの変数間のそれぞれの相関係数を表しています.
(第2ステップ) VIFの計算
次に,出てきた相関係数を用いてVIFを計算します.上の定義式に当てはめてやると,それぞれのVIFは,
![]()
![]()

この結果,有業人員と実収入の間には,強い相関があり,多重共線性を起こしてしまう可能性があることが分かりました.
※練習問題
1980年,1990年,2000年についてVIFを求め,それぞれの年において,どの変数間に多重共線性を起こす要因があると考えられるかを答えなさい.