
経済データ処理実習 第3講 「これぞ表計算!」
|
| Ⅰ.準備と前回のおさらい | |
| Ⅱ.関数の利用(合計,平均,最大値,最小値,中間値) | → 練習問題1. |
| Ⅲ.散らばりの尺度(分散と標準偏差) | → 練習問題2. |
| Ⅳ.偏差値の計算 | → 練習問題3. |
Ⅰ.準備と前回のおさらい
まず,今日の実習の準備と前回のおさらいをします.
(1)準備-「From Teacher」フォルダの利用-
実習に使うための色々なデータは,From Teacherフォルダにあります.
各自で自分のパソコンの「マイドキュメント」などにコピーして利用してください.
手順:「マイコンピューター」 → 「‘wnf’のReportFolder(X:)」 → From
Teacher
→ 菅原宏太(経済)
菅原宏太(経済)フォルダの中に,「経済データ処理」というフォルダがあるので,それを開きます.
中に,「県民経済計算.xls」というExcelファイルがあるので,それを右クリックしてコピーし,
自分のパソコンの「マイドキュメント」などに貼り付けてください.
(2)前回のおさらい-オートフィル機能での連番付け-
コピーした「県民経済計算.xls」を開くと,都道府県名と各都道府県の1人当たり県民所得のデータが出てきます.
ここで,都道府県名の隣に連番付けをしましょう.
A列を選択して,新しい列を挿入し,空白列を作ります.前回のおさらいで,
北海道から順番に1,2,3,...と番号をつけましょう.
これらの説明は省略します.
(1)まず,沖縄の下にそれぞれを入力しておきましょう.
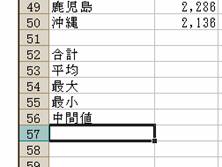
(2)次に,合計から求めます.
合計と書いたセルの隣のセルを選択し,ツールバーの「Σ」マークの横の▼をクリック,
出てきたプルダウン・メニューから「合計(S)」をクリック.
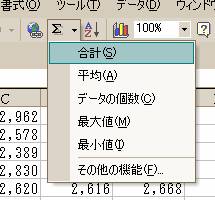
すると,合計と書いたセルの隣が右下図のようになります.
“=SUM”というのが,「合計します」という意味です.その後のカッコ内はデータの範囲です.
(B4:B51)となっていますので,「B4セルからB51セルまでの数値を合計します」というのが
ここの意味です.
このままでも構わないのですが,データはB50までなのでデータの範囲を修正しておきましょう.
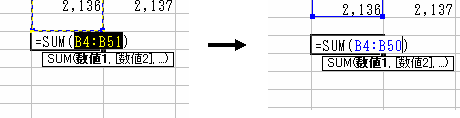
簡単ですね.もし地道に,=B4+B5+B6+...なんてやって合計を出していたら,
日が暮れてしまいます.
※練習問題1.
同様の手順で,平均,最大,最小,中間値を計算しましょう.
また,平成9年度,10年度,11年度についてもやってみましょう.
中間値はちょっと面倒です.プルダウン・メニューの「その他の機能(F)」を選び,
「関数の検索(S)」で中間値を検索し,出てきた候補の中から“MEDIAN”を選んでください.
データ範囲を聞いてきますので,合計などと同様にB4からB50を設定してください.
これらの統計量は,経済格差を測るときに,もう一度詳しく説明します.
簡単に言うと,分散も標準偏差も,データ集合(ここで言えば47個の都道府県データ)の散らばり具合を
計るものです.
まず個々のデータの散らばりは“偏差”で計ることができます.
偏差とは,個々のデータと平均値との乖離です.
(偏差は各データにつき,1つ出てくるので47都道府県データであれば,47の偏差が出てきます)

では,この偏差をまとめれば,データ集合の散らばり具合が分かるかと言うと,残念ながらそうは行かず,
偏差の合計は,平均値の性質により0になってしまいます.
(「ホント?」と思う人は確かめてみてください)
そこで,この偏差を2乗して平均をとり,それを「分散」と呼んで散らばりの尺度として用います.
(次式から分かるように,分散はデータ集合につき,1つです.)
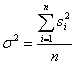
ところが,この分散,偏差を2乗していますので,単位も元のデータの2乗になってしまいます.
つまり,ここで扱っている1人当たり県民所得データの単位は千円ですが,(だから平均値は千円です)
分散は1000の2乗で,百万円となってしまいます.
「これでは良くない」ということで,(なぜ良くないかは,統計学や計量経済学の講義でならってください)
この分散の平方根(√)をとり,「標準偏差」と呼び,一般的な散らばりの尺度として用います.
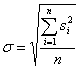
では,分散と標準偏差を計算してみましょう.
1.まず,先ほど入力した中間値の下に,「分散」,「標準偏差」と入力しましょう.
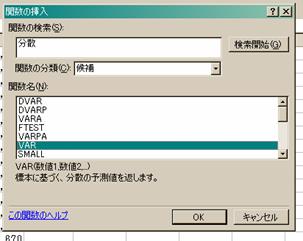
2.次に,先ほど中間値を求めた要領で,プルダウン・メニューの「その他の機能(F)」を選び,
「関数の検索(S)」で,分散(または標準偏差)を検索し,出てきた候補の中から下図のものを
選びます.
○分散は“VAR” ○標準偏差は“STDEV”
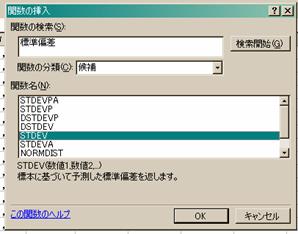
○ここで,範囲の指定を忘れずに! 指定は数値1という欄に直接入力しても良いし,
下図の赤丸部分をクリックすると,マウスのドラッグで表から自分で選ぶこともできます.

※練習問題2.
平成7年度以外のデータについても,分散と標準偏差を出してみましょう.
タイトルを見て,嫌なイメージを持った人は多いと思います...
しかし,偏差値というのは,れっきとした統計量の1つなのです.
例えば...
社会科のテストとして日本史と世界史を選べたとしましょう.100人の生徒のうち,
60人は日本史を受け,残りの40人は世界史を受けたとします.
その時,社会科の成績として,生の100人の点数を比較できるかと言うのそれはダメです.
もし,日本史のテストはすごく簡単で,世界史のテストがすごく難しかったとしたら,
世界史を受けた40人にとって,そんな成績の付け方は不利です.
こうした,状況の異なるものを比較するときに使うのが偏差値です.
(もう少し詳しく言うと,偏差値とは「データの標準化」の応用です)
今回使っている都道府県データで,偏差値はどのように使えるかと言うと...
例えば,平成7年度の北海道の1人当たり県民所得は277.5万円ですが,
平成11年度には271.5万円に減少しています.これは,平成11年度の方が不況が深刻化している
からでしょう.
ただ,不況の影響は多かれ少なかれ他県にも及んでいるわけですから,他県の県民所得も
減少している可能性があります.
ここで,偏差値の登場です.
北海道の平成7年度と11年度の偏差値を求めて比較してみます.
もし,11年度の偏差値が7年度よりも下がっていれば,「北海道は他県より不況のダメージが大きい」
と言えます.
逆に,偏差値が上がっていれば,「不況が深刻になっている中でも北海道は他県よりはマシ」
と言えます.
説明が長くなりましたが,それでは偏差値を求めてみましょう.
1.まず,平成7年度の横2列に新しく列を挿入します.(D,E列を選択して右クリックから「挿入(I)」)
新しくできた列に,「標準化」,「偏差値」と入力しておきましょう.
2.次に,「標準化」という作業をします.北海道の標準化のセルを選択しておいて,関数を挿入します.
(中間値,分散,標準偏差を求めたやり方と同じです)
関数の検索欄には「標準化」と入力し,出てきた候補の中から“STANDARDIZE”を選択.
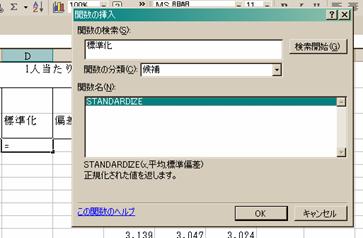
3.すると,次に幾つかの設定をしなければいけません.
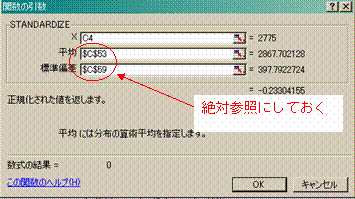
・まず,「X」は標準化したい数値ですから,北海道の平成7年度のデータのセル(C7セル)
を選びます.
・「平均」と「標準偏差」は,さっき出したものが使えますから,それぞれに該当するセルを選びます.
※このとき絶対参照にしておきましょう!
4.一つできれば後はカンタン.おなじみの■を下方へ沖縄県のデータまでドラッグして行きます.
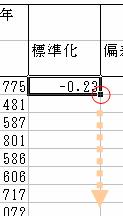
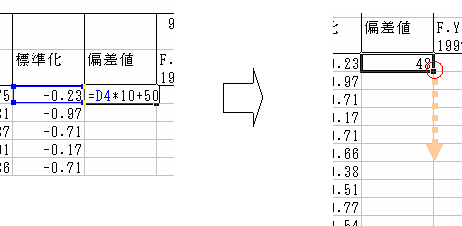
5.次に,再び北海道へ戻り,今求めた標準化変量(と呼びます)に,10を掛けて50を足します.
数式データは下図のように入力します.それから他県へコピーします.
※練習問題3.
以上の作業を,平成11年度のデータについてもやってみましょう.
そして,平成7年度と11年度の偏差値を比較してみましょう.
(1)北海道はどうなっていますか? そこから何が言えますか?
(2)東京はどうなっていますか? そこから何が言えますか?
(3)京都はどうなっていますか? そこから何が言えますか?
(4)あなたの実家の都道府県はどうですか?