
さまざまな<meta>タグの用途
<meta> タグには様々な用途があります。
このページでは <meta> タグの用途のうちいくつかを紹介します。
文字化けを防ぐ
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8">
ページ内で使用している文字コードを閲覧している機器に伝えることで、文字化けを未然に防ぐ効果があります。
詳しくはこちらを参照してください。 [ 文字化けについて ]
自動ジャンプ
<meta http-equiv="REFRESH" content="「秒数」;URL=「ホームページアドレス」">
ページの表示が完了後、「秒数」後に「ホームページアドレス」で指定したページに自動的に画面が切り替わります。
ページ閲覧者はとくに操作をする必要はありません。
サイトが移転した時などに、「新しいサイトはこちら」などの文言と共に使ったり、一定時間ごとに最新情報を表示したりする際に使います。
秒数を 0 に設定すると、一瞬で画面が切り替わります。
例 Yahooにジャンプ
<meta http-equiv="REFRESH" content="5;URL=http://www.yahoo.co.jp/">
上記の例では、5 秒後に Yahoo のページに切り替わります。
例 自動ダウンロード
<meta http-equiv="REFRESH" content="3;URL=http://www.xyz.com/myfile.zip"> <meta http-equiv="REFRESH" content="3;URL=myfile.zip">
「ホームページアドレス」の代わりに「特定のファイル」を指定すると、自動的にファイルをダウンロードさせることもできます。
ページ閲覧者のダウンロード操作が簡単になることが期待できます。
上記の例では、3 秒後に myfile.zip のダウンロードが始まります。
画面サイズの調整
スマートフォンなど携帯端末でウェブページを表示する際、機器によって画面のサイズが異なるので、ページのデザインによっては文章が画面からはみ出してしまったり、逆に小さすぎて見づらい場合があります。
そのような時は、下記のような <meta> タグを入力しておくと、機器の画面サイズ (device-width) に合わせて画面がレイアウトされるので、ページの内容が画面をはみ出したり小さすぎたりする問題を回避できます。
<meta name="viewport" content="width=device-width,initial-scale=1">
検索エンジン対策(SEO)
Google などの検索サイトは、検索結果の情報を蓄えるために、ボット(BOT)と呼ばれるプログラムに常時インターネットを巡回させています。ボットはページ内のリンクを機械的にたどり、各ページに記載されている内容を分析し、サイト情報を日夜整理しているのです。
そのようなボットに対して、<meta> タグを使うことによって、さまざまな情報を伝えることができます。
たとえば自分のサイトの説明文を伝えたり、アクセスして欲しくない領域を設定したりできます。
- ただしこれらの設定はあくまでサイト作成者側の要望なので、検索サイトの都合により受け入れられない、無視される場合はあります。
例 検索キーワードの指定
<meta name="keywords" content="「キーワード」,「キーワード」,「キーワード」"> <meta name="keywords" content="京都産業大学,産大,京産,京産大,ワンキャンパス,チャレンジ支援,学部横断教育,グローバル,キャリア教育">
検索サイトに、自サイトを検索する際に使って欲しいキーワードをボットに対して提案することができます。
検索サイトに自分のページが掲載されやすくなる効果が期待できます。
上記の例では、「京都産業大学」や「産大」などのキーワードで検索した時にサイトが表示されやすくなります。
- 「キーワード」の部分を 「,(カンマ)」で区切って何個でも指定できます。
- 必要以上に多量のキーワードを記載したり、実際の内容と異なるキーワードを設定すると、ボットに「不適切」と判断され、無視される場合もあるので注意しましょう。
- METAキーワードタグ内の前半に記述されているキーワードがより重要視されるので、ヒットさせたいキーワードはMETAタグ内の前半に記述するようにすると効果的です。
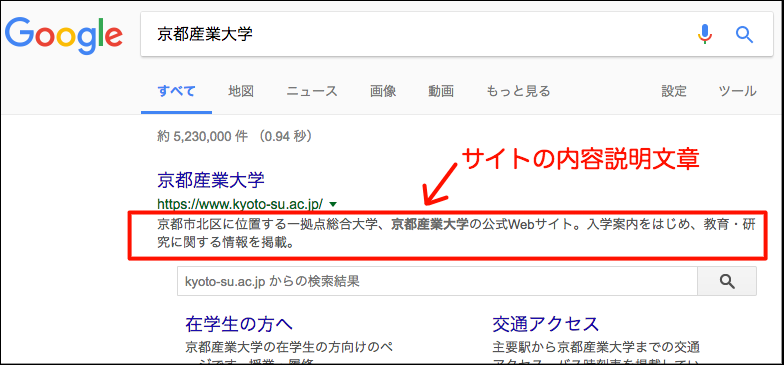
例 ページ概要の指定
<meta name="description" content="「サイト説明文」"> <meta name="description" content="京都産業大学の在学生の方向けのページです。授業・履修についてや学生支援に関わる情報を掲載しています。">
このMETAタグを記述することで、Google などの検索結果画面に表示されるサイトの「内容説明文章」をボットに対して提案できます。
このタグを指定しないと、通常はページの先頭部に書かれている内容やTITLEタグの内容などを使って自動的に説明文章が作られるので、文章の内容が意図しないものとなる場合があります。
検索サイトを利用するユーザーは、この内容を見てサイトにアクセスするかどうか判断する事が多いので注意して文章を作成しましょう。
- 必要以上に長い文章を書き込むのは得策ではありません。説明文の長さが長すぎると検索サイトに無視されてしまうからです。
例 ボットの巡回を制限する
検索サイトが稼働させているボットは、見つけたページ内のリンクをたどって自動的に他のページを調査する作業を繰り返します。
しかし登録されたくないページもあるでしょうし、逆に検索サイトに最新の情報を掲載してもらえるよう積極的にボットに巡回してもらいたい時もあります。
こういったボットの巡回経路を制御するには、下記のコマンドが有効です。
- ただしこれらはあくまで「サイト側のお願い」にすぎないので、ボットがこのルールを必ず守ってくれるとは限りません。
そのぺージとそこからリンクしているページの両方とも巡回拒否
<meta name="robots" content="none">
原則的にボットの立ち入りを拒否します。
検索サイトに該当ページやそのリンク先はすべて掲載されなくなります。
そのページの調査・登録を許可する
<meta name="robots" content="index">
通常はこの設定です。
<meta> タグをとくに記述しない場合と同じです。
そのぺージのみ調査・登録を許可、ページ配下のリンクを辿るのは拒否
<meta name="robots" content="index,nofollow">
該当ページは検索サイトに登録されますが、そこから辿れるリンクに関してはボットの立ち入りを拒否します。
そのページを調査・登録することを拒否
<meta name="robots" content="noindex">
検索サイトにページを登録されたくない場合に使用します。
検索サイトの検索結果画面に表示されなくなります。
ページ内の存在するリンクに関しては、ボットは通常通り巡回します。
そのページとリンクされている全てのページの調査・登録を許可
<meta name="robots" content="index,follow">
そのページ内の画像が検索対象となるのを拒否
<meta name="robots" content="noimageindex">
画像検索などに、該当ページ上の画像が掲載されるのを拒否します。
サイト内の写真などを検索サイトに無断掲載されたくない時に便利です。
ページ内の情報を記憶することを拒否
<meta name="robots" content="noarchive">
ボットがページ内を調査すること自体は許しますが、ページの内容を記憶することを拒否します。
ページ内リンクから辿った先については、通常通りの動作です。
検索サイトによっては「キャッシュ機能」などによって、ページの過去の内容を記憶する機能を備えている場合がありますが、noarchive を指定しておけば、検索サイト利用者がページの過去の情報を参照することができなくなります。
たとえばネットショップで商品やサービスの値段が変わる場合や(キャッシュ内の値段と現在の値段が異なるから)、メンバーシップ制のサイト(登録ユーザーしか閲覧できない)で用いると効果的なようです。
そのページおよびリンク先の調査・登録をすべて拒否
<meta name="robots" content="noindex,nofollow,noimageindex,noarchive">
content="none" と同様の動作。
いろいろと拒否します。
ボットに後日、再巡回させる
<meta name="revisit_after" content="30 days">
ボットが訪れた際、後日再度訪問させたい場合に記述します。
上の例は、30日後にまた訪問するよう要請しています。
- ただし検索エンジンの都合によりスケジュールが守られない場合はあります。
閲覧者のブラウザのキャッシュを制御する
<meta http-equiv="pragma" content="no-cache">
この記述は、ボット用というより、通常の閲覧者に対する設定です。
通常、ブラウザはページの表示を高速化するために、ページの内容を記憶し、次回表示する際に記憶した内容を使う動作をします。
これは「キャッシュ」という機能で、殆どのブラウザに備わっている機能です。
「キャッシュ」機能によって処理は高速化しますが、過去の情報が誤って表示されてしまう場合があります。
この <meta> タグを記述すると、ブラウザによってページがキャッシュ(記憶)されるのを防ぎ、アクセスする度に最新のページを読み込ませる事ができます。
刻々と情報が変化するページなどで有効です。
ページ内容の期限切れを伝える
<meta name="Expires" content="December 25, 2020">
コンテンツの有効期限切れの日付を入力します。期限切れになると、検索サイトはあなたのページの情報をデータベースから削除します。
期間限定のイベントやキャンペーンページなどで有効です。