図1: Acrobotタスクにおける連結チェーンの制御
(https://www.gymlibrary.dev/_images/acrobot.gif より引用)
先の研究ではOpenAIGymのPendulumタスクを強化学習課題として用い,ニューラルネットの進化的学習を試みた.今回はタスクをAcrobotタスク(連結チェーン制御)に変えて同様に学習を試みた.用いた進化的アルゴリズムは先の研究と同じ「進化戦略アルゴリズム」である.AcrobotタスクについてはOpenAIGymのwebページを参照されたい.
図1: Acrobotタスクにおける連結チェーンの制御
(https://www.gymlibrary.dev/_images/acrobot.gif より引用)
トルクを与える箇所はチェーンの連結部である.元のコードではチェーンのフリーエンド先頭部を図の黒線(チェーン固定点から上部にチェーン全体の半分の長さ)より高くすることが目標であり,目標が達成されたとき,もしくは所定のステップ数に到達したときに1エピソードが終了される.本研究ではコードを改造して,1エピソードの間,フリーエンド先頭部をできるだけ高く保つことを目標とした.チェーンが上方向に倒立したときフリーエンド先頭部が最も高い位置にあり,その状態をできるだけ長く保つほどより良く制御できたと言える.
また,元のコードでは入力可能なトルクは離散値であり,「左」「右」「入力なし」の3通りである.本研究ではニューラルネットの出力層ユニットから出力される実数値をそのままトルク入力値として用いた.値の範囲は -1.0 < トルク値 < 1.0 である.
チェーンの状態としてコントローラが観測できる値は6種類ある(詳しくはこちら).これらの値を -1.0~1.0の範囲に正規化してニューラルネットへの入力に用いる.用いたニューラルネットは3層全結合のMLPであり,活性化関数はtanh,入力層ユニット数6,出力層ユニット数1である.中間層ユニット数は4,8,16,32を試したところ,4のときだけ他の3通りより有意に劣り,それ以外には有意な差はなかった.したがって,この4通りでは8のとき性能とモデルサイズのバランスが最適とわかった.
進化戦略アルゴリズム(Evolution Strategy; ES)のパラメータは表1の2通りを用いた.実験の結果,設定(b)のほうが設定(a)より有意に性能が高いことがわかった.ESは広域的探索が苦手な手法のため,集団サイズ(1世代で生成する子個体の数)を大きく設定したことでその弱点が補われ,学習性能が向上したと考えられる.この結果は振り子課題のときと一致している.
表1: 進化戦略アルゴリズムのパラメータ

学習曲線の例を図2に示す.同じ設定で11回学習を行い,最良・メジアン・最悪試行の3回をグラフに示している.最終的な評価値は最良試行と最悪試行の間で大きな差がなく,試行間のばらつきが小さい.つまり,ESが初期解に依存せずロバストにMLPの結合強度としきい値を学習できたと言える.
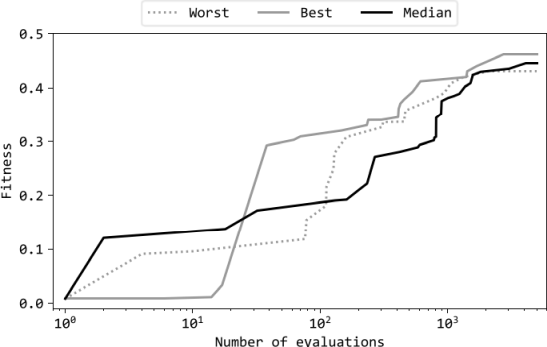
図4: 学習曲線 (設定(b),中間層ユニット数8の場合)
前記の最良試行における学習の開始時と終了時のニューラルネットがチェーンを制御したとき,チェーンのモーションはそれぞれ動画1,動画2の通りであった.動画1より,学習前のニューラルネットはチェーン先頭部の高さをほとんど上げられていないことがわかる.一方,動画2より,学習後のニューラルネットはチェーンをスイングさせて先頭部の高さを上げることに成功している.しかし,チェーンを倒立させてその状態を維持させることはできていなかった.このシステムではトルクの作用点が連結部のため,連結部より先のアームの回転運動を制御することは困難であったと考えられる.