図1: 振り子の制御
ニューラルネットの適用対象問題が判別や回帰であり,学習用データとして入力と教師信号の組合せが得られている場合には,学習方法として勾配降下法が用いられている.一方,ロボットなどの制御問題の場合には誤差関数の勾配の計算を必要としない強化学習法が適している.本研究では,ニューラルネットの強化学習法として進化的アルゴリズムを用いる方法を研究している.その例として,倒立振子を制御するニューラルネットの強化学習を,進化的アルゴリズムの1つである「進化戦略アルゴリズム」を用いて試みた.
倒立振子の制御とは,振り子が倒立するように適切なトルクを与える問題である.コードはOpenAIGymのPendulumを一部改造して用いた.
https://www.gymlibrary.dev/environments/classic_control/pendulum/
図1において,円弧の形状で示された矢印は現在の状態でコントローラが振り子に加えたトルクの向きと大きさを表現している.初期状態では図2のように振り子が下向きに静止しており,この状態から,できるだけ素早く図3のように振り子を倒立させて,目標状態を維持することを制御目標とする.
図1: 振り子の制御

図2: 振り子の初期状態

図3: 到達すべき目標状態
ここで,与えられるトルクには上限があり,その上限値で同じ方向へ継続的に力を加えても,振り子を倒立させることはできない.振り子を倒立させるためには振り子を左右にスイングさせて十分な角速度を獲得させる必要がある.
コントローラが観測できる振り子の状態は,cos(Θ),sin(Θ),角速度である.角度Θは目標状態のとき0,初期状態のとき|Θ|=Πである.この3つの観測値を(正規化したうえで)ニューラルネットへの入力として用いた.一方,ニューラルネットからの出力値を使って振り子へのトルクを決定した.ニューラルネットは3層全結合のMLPであり,活性化関数はtanh,入力層ユニット数3,出力層ユニット数1である.中間層ユニット数は8,16,32を試したところ,8の場合は他の2つを有意に下回り,16と32には有意な差がなかった.したがって,この3通りでは16のとき性能とサイズのバランスが最適とわかった.
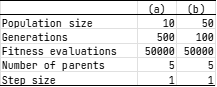
進化戦略アルゴリズム(Evolution Strategy; ES)のパラメータは表1の2通りを用いた.実験の結果,設定(b)のほうが設定(a)より性能が高く,特に中間ユニット数8のときは(a)より(b)が有意に良いことがわかった.ESは広域的探索が苦手な手法のため,集団サイズ(1世代で生成する子個体の数)を大きく設定したことでその弱点が補われ,学習性能が向上したと考えられる.
表1: 到進化戦略アルゴリズムのパラメータ
学習曲線の例を図4に示す.同じ設定で11回学習を行い,最良・メジアン・最悪試行の3回をグラフに示している.最悪試行の評価値は最良・メジアン試行の2つより大きく下回っているが,メジアン試行は最良試行と同程度に良い評価値が得られるまで学習できていることがわかる.
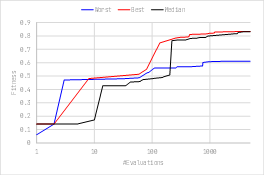
図4: 学習曲線 (設定(a),中間層ユニット数16の場合)
前記の最良試行における学習の開始時と終了時のニューラルネットが振り子を制御したとき,それぞれ動画1,動画2のように振り子が制御されていた.動画1より,学習前のニューラルネットは振り子を左右にスイングさせてはいるが倒立には成功していないことがわかる.一方,動画2より,学習後のニューラルネットは振り子を素早く倒立させ,かつその後はトルクをゼロにして倒立状態を維持させていることがわかる.