最も基本的なデータ構造である配列の実践的使用法を修得しよう。ただし,ここでは1次元配列のみを対象とする。
配列の宣言は,次のように, 要素の型 配列名[要素数] という形で行われる。
int a[10]
この宣言により,int 型の 10 個の要素 a[0], a[1], ..., a[8], a[9] がメモリ上に整然と並んだ配列が用意されて,その配列の名前が a となる。
| a[0] | a[1] | a[2] | a[3] | a[4] | a[5] | a[6] | a[7] | a[8] | a[9] |
上のように宣言された配列の場合, a[10] という要素は存在しない。 しかし, a[10] という存在しない要素をプログラム中で参照したとしても,コンパイル時にはエラーは出ない。 しかし,そのプログラムは期待した通りには動かないだろうし,a[10] に何かの値を代入しようとした場合,それは他のメモリ領域を破壊することになり,プログラムがクラッシュする原因となる。
型が必要とするバイト数および変数や配列に割り当てられたバイト数を得るための演算子 sizeof がある。これを用いて,宣言済みの配列の要素数を得ることができる。
sizeof 演算子は, sizeof(型名) または sizeof(変数名) のように使用することで,指定された型が必要とするメモリサイズまたは変数に割り当てられたメモリサイズを得ることができる。得られる数値はバイト単位である。
これを用いると,要素数を明示的に指定することなく,初期値を与えるだけで宣言された type 型配列の要素数が何個であったのかを, sizeof(a)/sizeof(a[0]) という形で得ることができる。
main()
{
int a[] = {1, 2, 3, 4, 5};
printf("number of elements is = %d\n", sizeof(a) / sizeof(a[0]));
}
number of elements is = 5
ところで, sizeof は演算子であり,関数ではない。実際,引数が変数名の場合には括弧は不要であり,先ほどのプログラムの一部は次のように書いてもよい。
printf("number of elements is = %d\n", sizeof a / sizeof a[0]);
また,sizeof 演算子の値は,実行時ではなく,コンパイル時に決定される。したがって,その値は定数である。
配列とポインタには密接な関係がある。その理解は,配列を扱う関数をコーディングするには,不可欠である。
整数型配列 array と整数型ポインタ ptr とが次のように宣言されていたとする。
int array[10];
int *ptr;
このとき,array に添字をつけてたとえば array[3] としたものは int 型の変数であり,それに整数値を代入することができる。 しかし,添字をつけない array そのものは,配列の先頭要素 array[0] を指す int 型ポインタ定数となる。 すなわち array == &array[0] である。 (例外もある)
したがって,次のようにして ptr に array の値,すなわち array[0] を指すポインタ値を代入することができる。
ptr = array;
ここで,array はポインタ定数であることに,注意しよう。したがって,array に何かのポインタ値を代入することはできなので,次はコンパイル時にエラーとなる。
array = prt; /* エラー */
また,array に整数 n を加えた式 array + n は array[n] を指すポインタとなる。すなわち, array + n == &array[n] であり, *(array + n) == array[n] である。
配列を引数にとる関数を作るときには,上で述べた,配列とポインタの関係を理解することが不可欠である。
ウォーミングアップで作成した,配列中で最大の値をもつ要素の添字を返す関数 arrayMaxValueIndex の宣言部分をみてみよう。
int arrayMaxValueIndex(int array[], int n)
array は配列のように見えるが,じつは配列ではなく,ポインタ変数である。したがって,本来は次のように書くべきものである。
int arrayMaxValueIndex(int *array, int n)
しかし,関数の仮引数においては,ポインタであるべきものを配列のように見せ掛けることが許されている。なぜなら,仮引数 array
に対応する実引数は配列であることを想定している場合は仮引数も配列であるかのように書く、ということが自然だからである。(仮引数と実引数)
しかしながら,配列要素の個数を指定しようとして次のように書いても,これは無意味であり,無視される(コンパイルエラーにもならない)。
int arrayMaxValueIndex(int array[N], int n)
それが証拠に,この関数内で array のサイズを得ようとしてsizeof (array)
としても,この値は,ポインタ変数1個のサイズ(多分,4バイト)となる。
関数に引数として引き渡される配列は,配列全体ではなく,配列の先頭要素へのポインタである。したがって,実引数である配列の個々の要素はコピーされることなく,そのまま関数の内部から参照されることとなる。 すなわち,仮引数として与えられた配列の要素を関数の内部で書き換えると,実引数である配列の要素が書き換わる。
このことは,多くの場合,次の意味で非常に有益なことである。
しかし,関数内で不用意に仮引数の配列要素を書き換えることのないように,注意する必要がある。
配列を使ってプログラミングをするとき,宣言された配列の大きさ全体を常に使用することは稀であり,普通はその一部を使用する。したがって,配列のどの部分をどのくらい使っているか,という情報が不可欠となる。その情報を含めたデータ構造について考える。
もっとも簡単な方式の一つには,配列の先頭から常に使用することとして,現在使用している個数(データ長)を情報として付け加える方法がある。先ほどの,ウォーミングアップで作った関数 arrayMaxValueIndex(int data[], int n) が,その一例である。
この方式の利点は,考え方と構造が簡単であり,プログラミングが容易であるという 点である。また,難点は,配列の他にデータ長という情報を入れる変数が必要であるという点である。
では,このデータ構造を用いて動く関数を作ってみよう。最初は,配列の内容を表示するだけの関数である。
arrayPrint(int array[], int n) は array[0]から array[n-1] までの整数値データを表示し,最後に改行を入れる。
void arrayPrint(int array[], int n)
{
int i;
for (i = 0; i < n; i++) {
printf("%3d", array[i]);
}
printf("\n");
}
書式文字列にある "%3d" は,整数値を(十進数表記で)3桁の幅をとって表示する指定である。
では,練習問題をしてみよう。初めは、簡単な探索の問題である。
練習問題1: 整数型配列 array の,array[0] から array[n-1]までの n
個の要素の中から,指定された値
val をもつ要素を探して,その添字を返す関数
int arrayIndex(int array[], int n, int val)
を作れ。ただし,そのような要素が複数個あるときには,その中で最初の要素(添字が最小のもの)の添字を,またそのような要素がないときには,-1を返すものとする。
解答解説
では次に、引数に与えられた配列の内容を変化させる関数を作ってみよう。
練習問題2: 整数型配列 array の,array[0] から array[n-1] までの n
個の要素の内容を逆順に並べ替える関数 arrayReverse(int array[], int n) を作れ。
解答解説
標準ライブラリ関数にある qsort は,この「配列+データ長」というデータ構造に対して働く関数である。
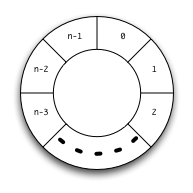
時計の文字盤の数字のように,環状に並んだ n 個の物があり,
それら一つひとつを表すデータを配列 a の各要素に入れたとする。
この場合,最後の要素 array[n-1] が表す物の次には array[0] が表す物が来る。
すなわち,この配列の添字は
..., n-3, n-2, n-1, 0, 1, 2, 3, ..., n-3, n-2, n-1, 0, 1, 2, 3, ....
と巡回的に動くと思ったら良い。
このような巡回的な添字を扱うのに便利なものが剰余算演算子 % である (a % b は a を b で割ったときの余り)。
詳しくは,巡回的な添字を参照。
配列の要素自身に,データの終端であることの情報を含ませることにより,データがどこまで入っているかを表すことができる。 最後のデータが入っている要素の次の要素に,あらかじめ決めておいた終端であることを示す値(終端記号)を入れることでデータの長さを表すわけである。
たとえば,終端記号を -1 としたとき,3,2,4,1,5というデータを,この方式で配列に収納すると,次のようになる。
| 3 | 2 | 4 | 1 | 5 | -1 |
この方式の利点は,配列の値だけで,その中のどこまでに有意なデータが入っているかが分かる点である。すなわち,データ数を表す変数が必要ないということである。
欠点は,終端記号すなわち終端を表す値は,データとしてはあり得ない値として選ぶ必要がある点である。そのような値を選ぶことができない場合には,この方式を用いることはできない。 また,終端記号を入れる要素のために,データ長+1個の要素が必要となる点もある。 さらに,データ長を求めるためには,終端記号が見つかるまで,配列を最初から探索する必要があることも欠点である。
C言語での文字列にはこの方式が用いられている。その終端記号は NULL 文字 '\0' である。
それでは,このデータ構造を扱う関数をいくつか作ってみよう。
ここでは,配列要素の型は整数型とし,終端記号は #define END -1 とマクロ定義されたものを使うこととする。
次は,終端記号をもつデータ列を表示する関数である。
void dataPrint(int data[])
{
int i;
for (i = 0; data[i] != END; i++) {
printf("%4d", data[i]);
}
printf("\n");
}
仮引数においては,何々型配列は何々型ポインタと同じである。したがって,引数に渡された配列 data[] をポインタ *dataとして扱って次のようにコーディングすることもできる。このようにすると,配列の添字として用いた変数 i が不要となる。
void dataPrint(int *data)
{
while (*data != END) {
printf("%4d", *data);
data++;
}
printf("\n");
}
練習問題3: 終端記号 END をもつ整数型配列の,データ長を返す関数 int dataLength(int data[]) を作れ。解答解説
練習問題4: 終端記号 END をもつ整数型配列内のデータを,他の整数型配列へ複写する関数を作れ。今回は,関数名を含めて関数仕様も考えることが問題である。解答解説
関数名や引数が指定されていない時は,それを考えることも問題に含まれている。
整数型配列 array とそれに入っているデータの数 n に対して,次の操作を行う二つの関数 arrayInsert と arrayDelete とを作れ。
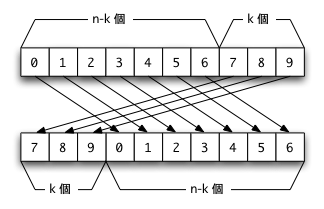
長さ n の配列 a の内容を,要素 k 個分だけ後ろにずらす関数 arrayRotate(int a[], int n, int k) を作れ。ただし,長さ n の配列の終端からはみ出た部分は,ずらすことによって出来た先頭の空き部分にもってくることとする。
すなわちa[0], a[1], ..., a[n-k-1] の内容をそれぞれ a[k], a[k+1], ..., a[n-1] へ移し,a[n-k], a[n-k+1], ..., a[n-1] の内容をそれぞれ a[0], a[1], ..., a[k-1] へ移す。
練習問題3で作った関数 dataCopy(src, dest) は,終端記号 END に出会うまで際限なく複写を行う。これでは,複写先の配列 dest のサイズを超えて複写されてしまう可能性があり,非常に危険なことである。そこで,関数を改造して, 指定されたデータ数 n 以上は複写を行わない関数,dataCopyn(src, dest, n) を作れ。( n 個目のデータの複写は行わずに,代わりに END を入れる)
解答解説(期限後に公表)終端記号 END (= -1) をもつデータ列二つを,辞書式順序で比較し,その結果を整数値で返す関数を作れ。ただし,データは非負整数(0 以上の整数)であるとする。
ここで,データ列の辞書式順序による比較とは,二つのデータを互いに先頭の要素から順に比較していき,互いに異なる要素に最初に出会ったとき,その要素の大小関係をデータ全体の大小関係と定める比較方法である。
たとえば,{1, 2, 3, 4} と {1, 2, 4, 2} とを比較すると,互いに異なる要素で最初のものは3番目の 3 と 4 とであるので,{1, 2, 3, 4} < {1, 2, 4, 2} という比較結果となる。
ただし,{1, 2, 3} と {1, 2, 3, 4} とのように,一方が他方の先頭部分に含まれるときには,データ長の長い方が大きいとする。したがって, {1, 2, 3} < {1, 2, 3, 4} である。
関数の戻り値は,f(a, b) のように使った場合,次の通りとする。