Webの普及に伴い,Webアクセシビリティの重要性がますます高まっており,設計ガイドラインの策定,規格化,検査手法・自動化ツールの開発などが活発に進められている.
Webページのアクセシビリティを向上させるための設計ガイドラインの1つとして,"見出し,段落,リストなどの要素を用いて文書の構造を規定しなければならない"とされている.またこの例として,"見出しは,フォントサイズなどの違いで表現せず,見出し要素を用いて表現する"ことが挙げられている.
したがって,Webページの検査において,ページ中の論理的な「見出し」のうち見出し要素(h1~h6)を用いていないものを自動的に抽出できれば,アクセシビリティの向上に有効と考えられる.しかし,既存のWebページ検査システムではこのような自動抽出は実現されていない.
Web上のページに含まれる見出し要素(h1, h2, …, h6)の間に,HTMLソースコード上の共通的な特徴が存在すれば,その特徴を備えた要素であり見出しタグで表現されていない要素が,「問題見出し要素」の可能性が高いと考えられる.そこで,Web上のページに含まれる見出し要素の事例データから,見出し要素に共通する特徴を機械学習法によって導出する.
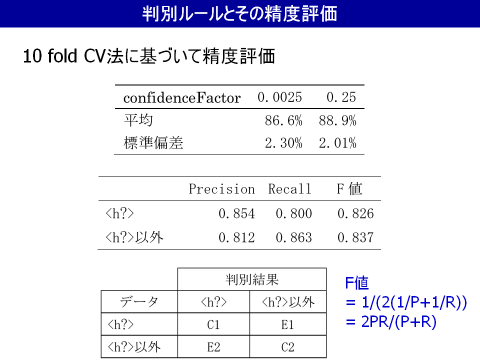
C4.5を用いることで,F値でおよそ80%程度の精度の判別が可能であることがわかった.