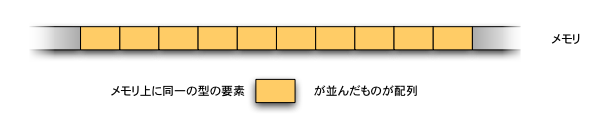
配列(array)とは,同一の型のデータを(メモリ上に)一列に(隙間をあけずに)並べたものである。違う型のデータを混在して並べて配列とすることはできない。 配列中の各データを,配列の要素(element)という。 配列には,その配列全体を指すための名前(配列名)がついている。
配列の各要素には,先頭を0番として,0, 1, 2, 3, ...と,順に番号がついている。 先頭が0番であることから,要素数が N 個の場合には配列の最後の要素は N-1番であることに注意しよう。
配列の i 番目の要素は 配列名[i]
という書き方で表される。この[ ] の中にある数(変数) i を,
配列に付けられた添字(そえじ)(index)と呼ぶ。
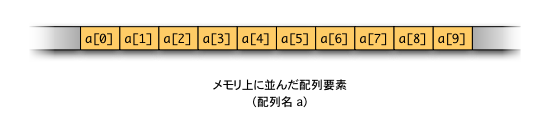
int a[10];
と宣言された配列は10個の要素を持っているが,
この配列に付けることのできる添字は 0 から 9 であり,
要素を全部書き上げると,
a[0], a[1], a[2], a[3], a[4], a[5], a[6], a[7], a[8], a[9]
となる。
これらの要素は次図のようにメモリ上に隙間をあけずに一列に並んでいる。
配列の宣言は,次のように書く。
要素のデータ型 配列名[要素の個数];
たとえば,int型(整数型)の要素を10個持つ,名前が a の配列は次のように宣言される。
int a[10];
配列を宣言したときに,次のようにして,その初期値を同時に設定する(初期化する)ことができる。この場合,10個のint型要素をもつ配列aが宣言されると同時に,その各要素の数値が,a[0], a[1], a[2],... の順に 10, 9, 8,... と設定される。
int a[10] = {10, 9, 8, 7, 6, 5, 4, 3, 2, 1};
初期値を書き並べてみたけれどもその個数を数えるのが面倒なとき,あるいは初期値の個数に応じて配列の要素数を決めたいときには,次のように,配列の要素数を空欄にしておくこともできる。
int a[] = {1, 2, 3, 4};
上のものは,次と同等である
int a[4] = {1, 2, 3, 4};
要素数が多い場合には,初期値をソースコードに書くのは大変だから, 普通は for 文などを用いて初期値を設定する.
int a[1000];
int i;
for (i = 0; i < 1000; i++ ) {
a[i] = 0;
}
上のプログラムの場合,配列 a の全ての要素を 0 に設定している.
C言語では,配列全体(配列内のすべての要素)を一度に取り扱うための実行文はなく,一つの配列全体を一度に他の配列に代入するようなことはできない。 たとえば,次のプログラムは誤りである。
int a[10], b[10];
a = b;
配列 b の各要素の内容を,配列 a の対応する添字をもつ要素に,すべて代入したければ,たとえば for 文を用いて,次のように各要素ごとに代入する必要がある。(他に,標準ライブラリ関数 memcpy や memmove などを用いる方法もある。)
int a[10], b[10];
int i;
for (i = 0; i < 10; i++) {
a[i] = b[i];
}
配列全体に割り当てられたメモリサイズ(メインメモリ上で割り当てられた領域のバイト数)は sizeof 演算子を用いて得ることができる。
次を実行すると,int 型のメモリサイズと,int 型の要素を10個もつ配列 a のメモリサイズが表示される。a のメモリサイズ sizeof(a) は,int 型のメモリサイズ sizeof(int) の値のちょうど10倍となっている。
(この値は使っているコンピュータや OS によって異なることがある)
#include <stdio.h>
int int main()
{
int a[10];
printf("sizeof(int) = %d, sizeof(a) = %d\n", sizeof(int), sizeof(a));
return 0;
}
sizeof(int) = 4, sizeof(a) = 40
配列を宣言するときに,要素数を指定せず,次のように初期値だけで宣言することがある。
int a[] = {1, 2, 3, 4};
この場合,aの要素数は,a 全体のメモリサイズを一つの要素(たとえば a[0])のメモリサイズで割ることにより,sizeof(a) / sizeof(a[0])
として得られる。したがって,次のようなコーディングが可能である。
int a[] = {1, 2, 3, 4};
for (i = 0; i < sizeof(a)/sizeof(a[0]); i++)
printf("%d ", a[i]);
このような書き方をする利点は,int a[] = {1, 2, 3, 4}; で宣言した配列の要素数を変更して, たとえば int a[] = {1, 2, 3, 4, 5}; としたときに, 他の部分を書き直さなくてもよい,という点である。
配列を用いたいくつかのサンプルプログラムを見て参考にし,実際にプログラムを作ってみる。
次のプログラムは,配列を宣言すると同時に初期化しておいて,すべての要素の数値を表示し,またその総和を計算し表示する。
#include <stdio.h>
int main()
{
int a[10] = {4, 2, 11, 4, 15, 7, 9, 12, 3, 6};
int i, sum;
for (i = 0; i < 10; i++) {
printf("a[%d] = %3d\n", i, a[i]); /* 配列内容の表示 */
}
printf("\n");
sum = 0;
for (i = 0; i < 10; i++) {
sum += a[i]; /* 総和の計算 */
}
printf("sum= %3d\n", sum);
return 0;
}
a[0] = 4 a[1] = 2 a[2] = 11 a[3] = 4 a[4] = 15 a[5] = 7 a[6] = 9 a[7] = 12 a[8] = 3 a[9] = 6 sum = 73
このサンプルプログラム1には,配列を for 文で操作するときに用いると良い,簡単なテクニックがある。 添字を動かす範囲の指定の書き方に注目してみよう。
for (i = 0; i < 10; i++) {
配列の要素数は 10 なので,その添字は 0, 1, 2, ..., 9 の範囲で動く。したがって,次のように書けば良さそうだが,そうはしていない。
for (i = 0; i <= 9; i++) {
この2通りの書き方のうち,どちらが良いだろうか。
i < 10 の 10 という数字は,そのまま配列の要素数を表している。i <= 9 の 9 という数字は,配列の要素数-1 を表している。
プログラムを書くときの思考ステップが少ない(引き算をしなくてよい)だけ,i < 10 の方が書きやすい。また,プログラムのコードを眺めたときに,配列の要素数がいくつであるかをとらえることが容易いのも,i < 10 の方である。
次のプログラムは,配列 a を宣言すると同時に初期化しておいて,その配列要素をすべて配列 b に逆順に複写し,それを表示する。
#include <stdio.h>
#define N 10 /* 配列の要素数 */
int main()
{
int a[N] = {4, 2, 11, 4, 15, 7, 9, 12, 3, 6};
int b[N];
int i;
for (i = 0; i < N; i++) {
b[i] = a[N-1-i];
}
for (i = 0; i < N; i++) {
printf("%4d", b[i]);
}
printf("\n");
return 0;
}
6 3 12 9 7 15 4 11 2 4
プログラム中では,
b[0] = a[N-1],
b[1] = a[N-2],
...,
b[N-2] = a[1],
b[N-1] = a[0]
という代入を行うために,
次の for ループを用いている。
for (i = 0; i < N; i++) {
b[i] = a[N-1-i];
}
このプログラムにも,配列を用いるときに非常に重要となるテクニックがある。それは,N に配列 a の要素数をあらかじめ定義(define)していることである(マクロ定義)。
#define N 10
プログラム中でこのように書いてあると,それ以降, N
という単語は全て 10
という文字列に置換されたのちにコンパイルされる。
そこで, 10 と書く代わりに N と書くことができるのである。
このように,定数として定義されたマクロを,マクロ定数 という。
マクロ定数を配列の要素数に用いるのは,
単にタイピングの手間を減らすためだけではなく,
プログラムの読みやすさおよび保守という点において,重要なテクニックである。
なぜなら,配列の要素数を 10 から,
たとえば 20 に変更する必要があるとき,次のように書き直すだけで,全ての変更が終わるからである。
#define N 20
もしも,このマクロ定義を使っていなければ,プログラム中の 10 という数値すべてを,それが a の要素数であることを確認して,20に変更する必要がある。
それどころか, for (i = 0; i <= 9; i++) と書かれたものがあったとき,この 9 が配列の最後の要素の添字であることを確認して,それを 19 に変更する必要がある。
また,プログラムの理解のしやすさという点から見ると, N ではなくて,
たとえば ARRAYSIZE のように,長いけれど意味がすぐにわかるマクロ名を用いた方が良い。
次のプログラムは,配列を宣言すると同時に初期化しておいて,その配列要素の数値の中で最大のものを表示する。
#include <stdio.h>
#define N 10 /* 配列の要素数 */
int main()
{
int a[N] = {4, 2, 11, 4, 15, 7, 9, 12, 3, 6};
int i, max;
max = a[0];
for (i = 1; i < N; i++) {
if (max < a[i]) {
max = a[i];
}
}
printf("max value = %d\n", max);
return 0;
}
max value = 15
プログラム中のfor文では,配列の要素を始めから見ていき,
それまでに見つけた最大値 max と,今注目している要素 a[i]とを比較し,
a[i] の方が大きければ,max の値をそれで置き直す。
また,max には始めに a[0] の値が入っており,
a[0] は max と比較する必要がないので, for文は i=1 から始まっている。
配列 a と b の同じ添字の要素を加え合わせたものを,それぞれ,配列 c の同じ添字の要素に代入し( c[i] = a[i] + b[i]),c のすべての要素の数値を表示するプログラムを作れ。
すなわち,配列をベクトルとみなして和をとることをせよ。
次のコードに書き加えることによりそれを完成させればよい。
#include <stdio.h>
#define N 10
int main()
{
int a[N] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int b[N] = {1, 1, 2, 2, 3, 3, 4, 4, 5, 5};
int c[N];
return 0;
}
実行結果は次のようになるはずである。
2 3 5 6 8 9 11 12 14 15
たとえば,int a[10];
と宣言された配列 a は, a[0] から a[9] までの要素を持っている。そして,これら以外の添字をもつ配列 a の要素,たとえば a[10] とか a[-1] とか,は実在しない。しかし,これらの存在していない要素をプログラム中で使用したとしても,Cコンパイラは何のエラーも警告も発しない。正常にコンパイルが終了し,コンパイルされたプログラムは実行可能となる。
では,次のようなプログラムを書き,コンパイルして,そのプログラムを実行したとしよう。
int main() {
int a[10];
a[10] = 7;
return 0;
}
このとき,プログラムは,メモリ上のどこかの場所を,実在もしていない要素 a[10] だと見なして,そこへ数値7 を代入しようとする。しかし,どこの場所が a[10] と見なされるかは,分からない。
多くの場合は,実在している要素 a[9] に引き続くメモリ領域にあると見なされるが,それも定かではない。
いずれにせよ, a[10] があると見なされたメモリ領域については,次の可能性がある。
これらのうち,どの場合になるかによって,プログラムの挙動が違ってくる。
a[10]=7 という代入によって,他の変数がもつデータが破壊されて,プログラムは期待通りの動きをしない。
どの場合も,正しいプログラムではないので修正の必要があるが,その直し易さにおいて違いがある。
以上のことをしっかりと認識して,配列を用いるときには,その添字が宣言された範囲を逸脱しないように,細心の注意を払う必要がある。
宣言された範囲外の添字をもつ配列要素への代入が,他の変数にどのような影響を及ぼすかを,次のプログラムを実行して見てみよう。
#include <stdio.h>
int main()
{
int x = 111;
int a[10];
int y = 222;
printf("x=%d, y=%d\n", x, y);
a[-1] = 33333;
a[10] = 44444;
printf("x=%d, y=%d\n", x, y);
return 0;
}
大学の10号館の環境では,多分,次のような結果になる。 a[-1] への代入によって,y の値が変化していることがわかる。
x=111 y=222 x=111 y=33333
また,配列の添字が宣言範囲を大きく逸脱した場合,OSから割り当てられたメモリ範囲外となり,セグメントエラーになることが多い。
int main()
{
int a[10];
a[999999] = 1;
return 0;
}
セグメントエラー
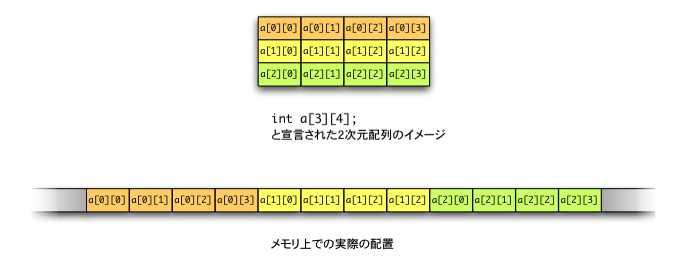
行列や表のように,2次元的な広がりをもって配置されたと考えるデータを取り扱うために,2次元配列がある。 その宣言は次のようになされる。
要素の型 配列名[行数][列数];
たとえば,int 型の要素が3行4列の形に並んだ2次元配列を宣言するには, 次のようにする。
int a[3][4];
このように宣言された2次元配列の各行,各列には, 0番から始まる番号がついていて,第i行,第j列の場所にある要素は
配列名[i][j]
という形で表される。
| 第0列 | 第1列 | 第2列 | 第3列 | |
|---|---|---|---|---|
| 第0行 | a[0][0] | a[0][1] | a[0][2] | a[0][3] |
| 第1行 | a[1][0] | a[1][1] | a[1][2] | a[1][3] |
| 第2行 | a[2][0] | a[2][1] | a[2][2] | a[2][3] |
行列の形に平面的にデータが配置されたと考えているのは,プログラムを作りあるいは使用している人間だけであり,コンピュータメモリ上での実際の配置は,1次元配列と同様に,隙間を空けずに一列に並べられている。
たとえば,int a[3][4]; と宣言された配列の場合,人間が考えるイメージと実際の配置の様子は次のようになる。メモリ上では,2次元配列の各行(横の並び)がひとまとまりになったものが並んでいることに注意しよう。
int a[M][N]; と宣言された2次元配列の要素の総数は M*N 個であるから,そのメモリサイズ sizeof(a) は,一つの要素のサイズ sizeof(int) の M*N 倍となっている。このことを次のプログラムで確かめよう。
#include <stdio.h>
int main()
{
int a[3][4];
printf("%d %d\n", sizeof(int), sizeof(a));
return 0;
}
4 48
2次元配列の初期値の設定も1次元配列と同様に行えるが,メモリ上の配置が行ごとにまとまっていることから,各行の数値を { } で括ったものを並べて,それを外側からもう一度 { } で括ることにより,初期値の構成を表す。
int a[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}};
次のプログラムは,配列 b の初期値を設定しておき,b の各要素の内容を a の対応する要素に代入し,a の各要素の数値を行列の形に表示する。
#include <stdio.h>
int main()
{
int a[3][4];
int b[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}};
int i, j;
for (i = 0; i < 3; i++) {
for (j = 0; j < 4; j++) {
a[i][j] = b[i][j];
}
}
for (i = 0; i < 3; i++) {
for (j = 0; j < 4; j++) {
printf("a[%d][%d] =%3d ", i, j, a[i][j]);
}
printf("\n");
}
return 0;
}
1次元配列と同様に,2配列全体の代入も一つの実行文で行うことはできない。2重のfor文を用いて行の添字と列の添字を動かし,各要素ごとに代入する必要がある。
a[0][0] = 1 a[0][1] = 2 a[0][2] = 3 a[0][3] = 4 a[1][0] = 5 a[1][1] = 6 a[1][2] = 7 a[1][3] = 8 a[2][0] = 9 a[2][1] = 10 a[2][2] = 11 a[2][3] = 12
2次元配列を用いた,実用的なプログラムを作ってみよう。
太郎,花子,次郎の3人の,国語,数学,英語,理科の成績がある。
| 国語 | 数学 | 英語 | 理科 | |
|---|---|---|---|---|
| 太郎 | 50 | 85 | 70 | 65 |
| 花子 | 90 | 80 | 85 | 65 |
| 次郎 | 70 | 75 | 65 | 80 |
次のプログラムは,この成績一覧表を表示し,各個人における4科目の成績の平均点を計算して表示し,また各教科における3人の平均点を計算して表示する。
#include <stdio.h>
#define PERSON 3 /* 人数 */
#define SUBJECT 4 /* 科目数 */
int main()
{
int record[PERSON][SUBJECT] = {{50, 85, 70, 65}, {90, 80, 85, 65}, {70, 75, 65, 80}};
float personalAverage[PERSON]; /* 個人平均点 */
float subjectAverage[SUBJECT]; /* 科目平均点 */
int i, j, s;
for (i = 0; i < PERSON; i++) {
s = 0;
for (j = 0; j < SUBJECT; j++) {
s += record[i][j]; /* s = record[i][0] + record[i][1] + record[i][2] + record[i][3] */
}
personalAverage[i] = (float)s / SUBJECT; /* s を浮動小数点数に型変換した後,科目数で割る */
}
for (j = 0; j < 4; j++) {
s = 0;
for (i = 0; i < 3; i++) {
s += record[i][j]; /* s = record[0][j] + record[1][j] + record[2][j] */
}
subjectAverage[j] = (float)s / PERSON; /* s を浮動小数点数に型変換した後,人数で割る */
}
for (i = 0; i < PERSON; i++) {
for (j = 0; j < SUBJECT; j++) {
printf("%8d", record[i][j]); /* i番目の人の各科目の成績を8桁で成績を表示 */
}
printf(" | %8.2f\n", personalAverage[i]); /* i番目の人の平均点を8桁(小数点以下2桁)で表示(|は区切りの縦線) */
}
for (j = 0; j < SUBJECT; j++) {
printf("--------"); /* 区切りの横線 */
}
printf("\n");
for (j = 0; j < SUBJECT; j++) {
printf("%8.2f", subjectAverage[j]); /* j番目の科目の平均点を8桁(小数点以下2桁)で表示 */
}
printf("\n");
return 0;
}
50 85 70 65 | 67.50
90 80 85 65 | 80.00
70 75 65 80 | 72.50
--------------------------------
70.00 80.00 73.33 70.00
上のプログラムを変更して,全成績(12個全部の成績)の平均点を,表の右下の角の位置に表示するようにせよ。
添字の個数をもっと増やして,多次元の配列とすることもできる。たとえば,
int a[2][3][4];
と宣言すると,a は2×3×4=24個の要素をもつ配列となる。
その要素は a[1][0][2] のようにして表される。
添字はやはり0から始まるので,a[i][j][k] と書いた場合の添字の範囲は
0 <= i < 1, 0 <= j < 3, 0 <= k < 4
である。
さらに詳しくは 多次元の配列についてを見るように。
4×4の形の配列 a の内容を,4×4の形の配列 b に,
下の図のように右に90度回転するようにして複写し,b の内容を表示するプログラムを作成せよ。
|
|
次のコードに書き加えて作成してもよい。
#include <stdio.h>
int main()
{
int a[4][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}, {13, 14, 15, 16}};
int b[4][4];
return 0;
}