|
みなさんがお持ちの携帯電話は,騒音環境下においても使用できます.
しかし,ノイズ(騒音)が相手に送信されると,通話品質が低下します. 本研究では,ノイズを除去するために「音声モデル」を用います. | 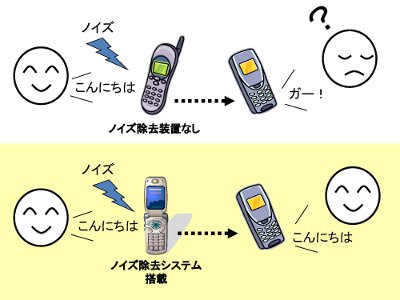 |
|
音声 X とノイズ D の和を観測信号 Y とします.
もし,Y=1 が観測されたとすると,音声 X は,"2"や"3"ではなさそうです. 一方,"0.5" や "0.6" ならありそうです. これを示したものが右の曲線(音声モデル)です. 最も音声らしい値を相手に伝えればノイズ除去が実現できます. | 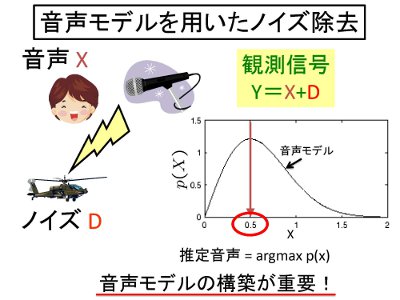 |
|
本手法で最も重要な要素は「音声モデル」の構築です.
従来は,平均的な音声モデルが利用されていました. 我々は,現在の音声に合わせて音声モデルを変化させる方法を提案しました. | 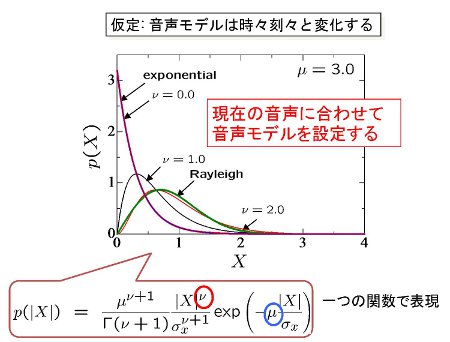 |
|
ノイズ除去結果のスペクトログラムです.
観測信号は,トンネル内のノイズ+音声です. 従来法1は,固定音声モデル, 従来法2は,以前構築した可変音声モデル, 提案法は,現在の可変音声モデルを用いた方法です. 新しい可変音声モデルにより,より強くノイズを除去できるようになりました. | 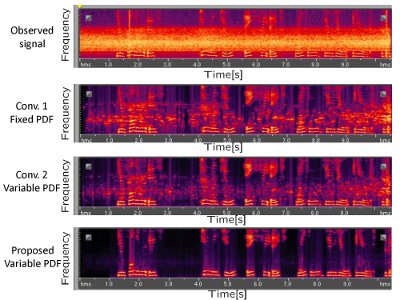 実験結果 |