日本語文字コード
テキストエディタの回で文字の扱いに関する注意事項を説明した。今回はもう少し突っ込んで、日本語のテキストファイルを扱う際に知っておくべき文字コードの説明と練習をしておこう。
日本語文字コードの種類
文字コードとは、例えば「あ」や「京」といった文字をどの数字で表すか、という取り決めである。
コンピュータの歴史の話になるが、初期のコンピュータはアルファベットと数字と記号を7bitの数値(0〜127の値)で表していた(ASCIIコード)。性能も低かったし、アメリカで開発されたものだから他の文字など不要だったからだ。
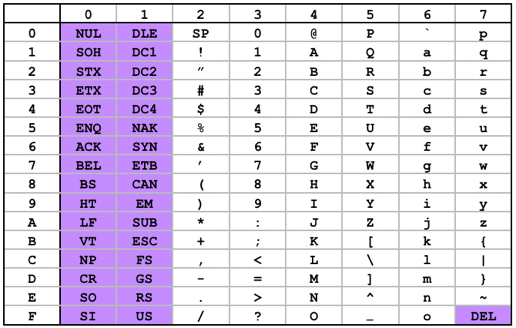
ASCIIコード表。上端の行は上位3ビット、左端の列は下位4ビットの値である。例えばAなら16進数で41、10進数で65の値である。紫色は制御コードであり、表示される文字ではない。
その後、世界中で使われるようになると、それまでの文字コードを拡張して8bit(0〜255)で表すようになった。その際、日本の規格ではカタカナが組み込まれた。しかし漢字は多すぎて8bitには収まりきらないし、複雑な字形を表示したり印刷することは当時の技術では無理だった。
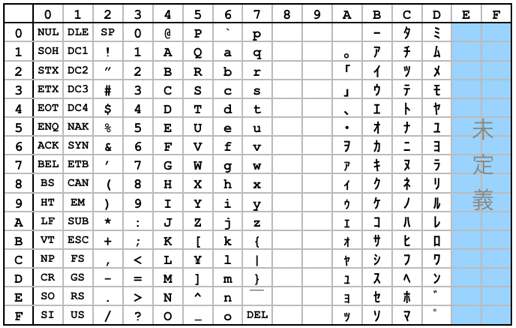
後に技術が進歩して漢字を取り扱えるようになり、幾つかの規格が産まれた。いずれの規格でも、複数バイト(多くは2バイト)のデータで1文字を表現するマルチバイト文字である。現在でも使用されている日本語の文字コードとしては次の4種類がある。
ISO-2022-jp (JISコード)
ASCIIコードと同様、7bitで日本語文字を表現する方式。電子メールなどの古い規格では7bit文字を取り扱うことになっており、今でも互換性のためJISコードが使われている。
EUC-JP (Extended Unix Code)
UNIXではこれまでの8bitコードを無視して、合理的な文字コードとして設計した。日本語以外にも、中国語のEUC-CNや韓国語のEUC-KRがある。8bitコードのいわゆる半角カナを扱おうとすると不具合が起きるという問題点がある。
Shift-JIS (SJIS)
パソコン向けにMicrosoft社とアスキー社などが開発した文字コード。8bitコードの半角カナを残しつつ、余ったコードに全角文字を割り当てている。古いソフトウェアや組み込み機器などではまだ使われている。
Unicode
世界中のすべての文字を統一的に扱うことが目的の文字コード。主要なコンピュータやスマートフォン向けのOSでは標準となっている。UTF-8やUTF-16を始め幾つかのバリエーションがあるが、macOS ではUTF-8を標準としている。
文字コードの互換性
以上のように日本語文字コードとしては4種類があるために面倒なことが起こる。つまり、ある文字を表す数値が文字コードによって異なる。例えばひらがなの「あ」はJISコードで16進数で2422、EUC-JPでA4A2、Shift-JISで82A0、UTF-8でE38182、UTF-16で3042と、まったく異なる値となっている。
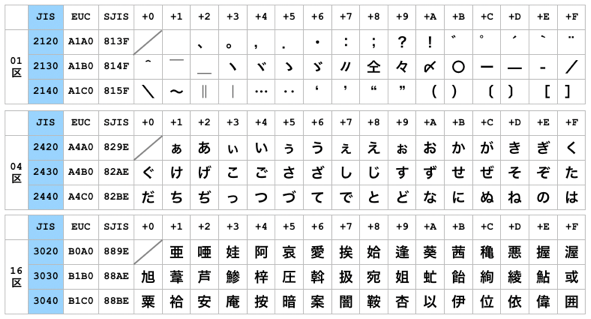
このため、ある日本語ファイルを、別の文字コードで解釈しようとすると正しい日本語にならない。例えばWebページを開いたときに、Webページが書かれた文字コードと、ブラウザが表示しようとする文字コードが一致しないと正しく表示されない(俗に言う文字化け)。あるいはWindowsパソコンで作成したテキストファイルをLinuxで開くと同様の問題が発生することがある。macOSのターミナルも扱う文字コードが設定されているので(標準でUTF-8)、異なる文字コードのファイルをcatコマンドで表示させると文字化けして読めない。
そこで、必要に応じて文字コードを変換してやる必要がある。変換する方法を2つほど紹介しておく。他にも専用アプリもあるだろう。
nkfコマンドを使う
nkf (Network Kanji Filter) は日本語文字コード変換のために開発されたコマンドである。標準ではインストールされていないので、自分でダウンロードしてコンパイルしてインストールする必要がある。配布元はこちらだが、インストール方法は少々難しいので説明はしない。使いたい人は自分で調べて欲しい(適切なキーワードで検索すれば簡単に見つかる)。
Emacsを使う
Emacsは文字コードの自動判別機能が搭載されている(たまに間違うことがあるが)。判別した文字コードは、モードラインの左端に表示されている。

JISコードならJ、EUC-jpならE、Shift-JISならS、UnicodeならUと表示される。
編集中のテキストファイルの文字コードを変更するには次のコマンド操作を使う:
C-x RET f (Controlを押しながらx、Return、fを順番にタイプする)
するとエコーラインに"Coding system for saving file (default utf-8)"などと表示されるので、変更したい文字コードに応じて次のように入力しReturnキーをタイプする。
JISコード: junet または ISO-2022-jp (JISやjisではだめ)
EUC: euc-jp
SJIS: sjis
UTF-8: utf-8
他にも理解してくれる表記方法がある。
最後に保存するのを忘れずに。
VS Codeを使う
VS Codeでも複数の文字コードを扱うことができる。文字コードの判別機能はあるようだが、初期状態では自動的に変えることはしてくれないようである。現在の文字コード設定はウィンドウの右下に表示されている。
開いたファイルが文字化けしている場合、この文字コードをクリックすると変更メニューが表示される。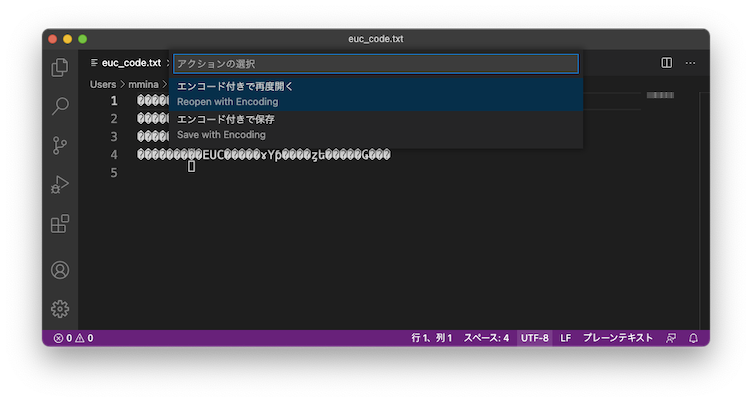
「エンコード付きで再度開く」を選択すると、文字コードのリストが表示される。VS Codeが判別した文字コードは一番上に出ているので(コンテンツから推測と書いてあるもの)、ほとんどの場合はそれを選べばよい。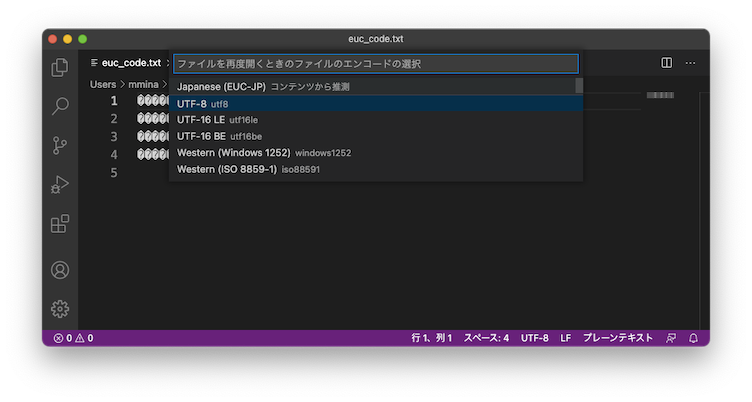
文字コードを切り替えると、内容が正しく表示され、右下の文字コードの表示も切り替わっている。
文字コードを変更して保存する場合は文字コードをクリックして「エンコード付きで保存」を選択して変更後の文字コードを選ぶ。
なお、VS CodeではISO-2022-jp(JISコード)は扱うことができないようであるが、バージョンアップや機能拡張で対応できるようになるかもしれない。
練習問題
1. まず、こちらのencode.zipをダウンロードする。リンクをクリックするとダウンロードし自動的に展開されて、Safariの保存用ディレクトリ(標準では「ダウンロード」)に"encode"という名前のフォルダが作られる。その中に幾つかファイルが入っている(後の課題用のファイルも入っている)。
2. 次に、euc_code.txt, jis_code.txt, sjis_code.txtをcatコマンドで表示させてみる。「ダウンロード」ディレクトリはターミナル上ではDownloadsという英語の名前になることに注意。cdコマンドで~/Downloads/encode/にカレントディレクトリを移動してから、catコマンドを使うとよいだろう。あるいは、作業しやすい場所にencodeディレクトリを移動させてもよい。どのように文字化けするか見ておこう(慣れれば文字化けのパタンから元の文字コードが何か推測できる)。
3. どれも文字化けして正しく表示されないので、文字コードを変換する。例として、EUC-JPのファイルをUTF8に変換してみる。
VS Codeの場合、「文字コードを変更して保存」を行うと、いきなり上書き保存してしまうので、先にeuc_code.txtをutf8_code.txtという名前で複製しておき、utf8_code.txtに対して文字コードを変換する(cpコマンドを使う)。
Emacsの場合、euc_code.txtを開き、上記で説明した操作でutf-8に変換し、utf8_code.txtという名前で保存する(Emacsで名前を付けて保存するにはC-x C-wとタイプする)。
4. 最後に、catコマンドでutf8_code.txtを表示させて正しく表示されることを確認する。
zipはアーカイブファイルと呼ばれる形式の1つ。アーカイブとは複数のファイルやディレクトリを1つのファイルにまとめて圧縮したもの。macOSのFinderではアーカイブしたいファイルやフォルダを右クリックし、メニューの「(選択したファイル名)を圧縮」を選べば作成できる。逆に、元に戻したい(展開したい)場合は、zipファイルをダブルクリックすればよい。ターミナルで作成あるいは展開するにはそれぞれzip、unzipコマンドを使う。
2.でどれかのファイルが正しく読めたらターミナルの文字コード設定がutf-8になっていない。
日本語文字コードに関する補足
半角カナ
冒頭で説明したようにコンピュータの進化の過程で1byte (=8bit)のデータでカタカナのみを扱えるようになった。このカタカナは俗に半角カナと呼ばれるものである。その後漢字を扱えるようになったさいに半角カナの扱いに少々混乱があり、問題になることがある。
EUC-jpではそれまで使っていた半角カナの領域を漢字を割り当てるために使った。つまり、それまでの半角カナは捨て去ったということである。一方、Shift-JISは、半角カナも特にビジネス用途では使われていたので、互換性のために残したまま漢字を割り当てている。このため、Shift-JISでは正しく表示できる半角カナをEUC-jpで表示しようとすると、漢字と勘違いしてデータ処理をしてしまう。文字化けする程度で済めばよいのだが、場合によってプログラムの動作がおかしくなり、異常終了してしまうという事態も起こりうる。
現在では半角カナは使う必要の無い文字なので、特に意図がないのであれば使わないようにしよう。
古い技術者の中には半角カナを見ただけで烈火のごとく怒り出す人もいるので注意。なお、JISコードでは原理上半角カナは扱えないし、Unicodeではまったく別の文字コードに割り当てられている。
機種依存文字
文字コードに含まれる文字は、別のJIS規格で決められている。しかし、文字コードによっては特定の文字を割り当てていない自由領域(外字領域)があり、機種(OS)によって記号などの異なる文字を割り当てている。このような文字を機種依存文字と呼ぶ。例えばWindowsとMacでは丸囲み数字(①②③④)やローマ数字(Ⅰ Ⅱ Ⅲ Ⅳ)などは扱いが異なっているので、例えばWindowsで作成したShift-JISコードのテキストファイルをMacで開くとこれらの記号が別の記号に化けてしまう。また、昔の携帯電話で使われていた絵文字も同じようにして扱われているので化ける可能性があった※1。最近のアプリケーションでは正しく解釈してくれることも多くなったが、時々化けたものを目にする。極力使わないようにしよう。
※1 悲劇的な例として「メールでうんこの絵文字ばかり使う彼氏に悩んでいます」が有名。同じ文字コードに割り当てていた絵文字が携帯会社によって異なっていたため、彼氏は🎵マークで送ったつもりが受け取った側は💩になっていた。
詳しくは「機種依存文字」で検索して欲しい。困ったことに事務職の方には丸囲み数字やローマ数字、ひいては半角カナが大好きな人も多いようで、文字化けしているメールや半角カナを使ったファイルを日常的に目にする。なお、Unicodeではこれらの記号も整理されて統一的に扱われているし、絵文字も標準として組み入れられた。一方で、絵文字の見かけがフォントによって異なっているため誤解が生じかねないという問題、異文化の絵文字が理解されない問題(例えば📛という絵文字は日本ではチューリップの名札(幼稚園でよく使われている)と理解できるが諸外国では"Tofu on fire(燃える豆腐)"と呼ばれたりしている)、肌の色やSOGI(性的指向と性自認)の多様性への配慮、などなど問題が少なくない。絵を文字として扱うのもどうかと思うが(文字がどのようにしてできたかを考えてほしい)、確かに便利ではある。
このページはMac上のSafariで確認して作製しているが、閲覧環境によっては執筆者の意図通りの見栄えとなっている保証はない。
異体字
漢字の中には同じ漢字として扱われるのに実際の書き方が異なるものがある。このような文字を異体字と呼ぶが、従来の文字コードには代表的な書き方しか収録されていないことが多い(Unicodeでは収録されている)。
例えば「高」という漢字は、「髙」という俗に「はしごだか」と呼ばれる表記もある。あるいは、「吉」も「𠮷」(つちよし)という表記もある。このような漢字は人名に多く、古いシステムではShift-JISやEUC-jpを文字コードに使っているため、代表的な漢字に置き換えるか、正しく表示できないことがある。Unicodeでは多くの異体字も収録されているが、すべてが収録されているかどうかは不明である。こればかりは標準で用意されていない文字なので諦めるしかない(名前なのでこだわる人もいるので注意が必要なのだが)。
もし君の名前がそういう漢字を使っていて、POSTやmoodleで正しく表示されていなければそういうことだ。