|
| xspim を起動したところ |
かつては、コンパイラでプログラムを組むよりもアセンブリ言語でプログラムを組むほうが速いプログラムができると言われた。 しかし、現在これは正しくなくなっている。 少なくとも C 言語について言えば、良いコンパイラを使うと普通に書いたアセンブリコードよりも速いプログラムが生成される。 もちろん、非常な努力をするなら、 コンパイラが吐くコードよりも速いコードを書けるのは当然である。 しかし、現実にはそれは難しい。その理由だが:
といった理由があげられる。
しかし、それにもかかわらず、人間がアセンブラでコードを書きたくなるこ とはある。それは:
等々という理由からである。
アセンブラは、ニーモニックで書かれた命令を2進数の命令に変換するだけ ではない。以下のような処理も行なっている。
いくつかの命令ではアドレスの指定が必要になる。 しかし、アドレスを直接プログラマが指定するのは大変な負担になる。
例えば、階乗を計算するルーチンがあるとして、 そのルーチンの先頭に分岐したいとしよう。 そのために「現在実行している命令から数えて××個先 (あるいは何バイト先) の命令へ分岐せよ」という命令を用いるとする。 その場合、現在の命令から数えて階乗ルーチンが何命令先にあるか、 命令数を自分で数えなければならない。 これを間違えずに行なおうとすると大変な負担になるし、 プログラムを書き直した場合、命令数が変わるから、数え直しになる。
このような「単純だが間違いやすい作業のくり返し」 は計算機自身にやらせるべきである。 そこで、階乗ルーチンの先頭の命令位置に適当な名前(このような名前をラベルという) を書いてやって、「これこれの名前の書いてある位置に分岐せよ」 とプログラムに記述しておけば、 命令数を数えて実際のアドレス指定を求める処理はアセンブラがやってくれるようになっている。 従って、普通どの CPU 用のアセンブラでも、 アドレスを直接書く代わりにラベルを使うほうが標準になっている。 例えば、無条件分岐 j では、
j ラベル
と書くようになっている。例えば、
j L
....
....
L: ....
のような書き方になる。 ここで L がラベルの名前であり、j L により、 L: とラベルが書かれている位置に分岐する。
コンピュータ内では、データもプログラムも2進数で表される。 プログラム内には、命令に対応するものだけが書かれるわけではなくて、 プログラム内で使われるデータも置かれているはずである。 (例えば、C 言語で printf("Hello, world\n"); と書いた時、"Hello, world\n" の部分は、機械語命令には対応しないデータである。)
そのため、アセンブラに対して、データの配置を指令することも当然でき なくてはならない。そのような指令をデータ・レイアウト指令(data layout directive) という。 例えば、後で使うアセンブリ言語では、次のように書くと文字列を配置で きる:
.asciiz "The sum from 0 .. 100 is %d\n"
.asciiz という指令の意味は、'\0' で終わるような文字列を配置する、ということ。 .asciiz という名前の最後の z は zero の頭文字から来ている。 .asciiz は、指定した文字列の最後に自動的に \0 を配置してくれる。 '\0' は、0を文字コードとして持つ特殊文字。 C 言語では、文字列の終りは '\0' を置くことによって表されるという約束になっている。
上の .asciiz の使用例は、次のようなデータレイアウト指令の列と同等である:
.byte 84, 104, 101, 32, 115, 117, 109, 32
.byte 102, 114, 111, 109, 32, 48, 32, 46
(中略)
.byte 32, 37, 100, 10, 0
84 は T の文字コード、104は h の文字コード、 101 は e の文字コード…となっている。
データ・レイアウト指令によって配置されたデータを参照する際には、 データレイアウト指令にラベルをつけておいて、それを用いてアクセスする:
message: ← ラベル
.asciiz "The sum from 0 .. 100 is %d\n"
アクセスの例はのちほど示す。
.asciiz 指令では '\0' で終わる文字列を配置するが、最後に '\0' を置い てほしくない時は .ascii 指令を用いる。
基本的には、1つのアセンブリ命令は1つの機械語に対応する。 しかし、機械語にそのまま対応するようなアセンブリ命令だけを使っていると、 プログラムが書きにくくなる。そこで、一つのアセンブリ命令が、 (一般には状況に応じて) 1個あるいは複数の機械語に対応するような疑似的な命令が用意されていることがあり、疑似命令と呼ばれている。 疑似的というのは、そのままで1つの機械語に対応するわけではないからである。
即値ロード疑似命令:
li Rdest, Imm (load immediate)
これは、Rdest で指定されるレジスタに即値 Imm をロードする(入れる)。 機械語には、これそのものの命令はない。 実際には、この命令は、次のような命令に翻訳すればよい:
ori Rdest, $0, Imm (or immediate)
あるいは、
addi Rdest, $0, Imm
に翻訳してもよい。
ここで、ori Rt, Rs, Imm という命令(or immediate)の意味は、 16ビットの(符号なしの)即値 Imm を32ビットにゼロ拡張したものと Rs の内容の間でビットごとの or 演算を行なったものを Rt に収める、 ということである。 C 言語風に書けば、Rt = Rs | Imm となる。 この説明だけでわからない人は「ori について」を見るように。
また、addi Rt, Rs, Imm という命令(add immediate)の意味は、 Rs というレジスタの内容に即値 Imm を加えたものを Rt に入れる、 ということ。 $0 には常に0が入っているので、addi Rdest, $0, Imm によって、 Imm の値が Rdest に入ることになる。
絶対値疑似命令:
abs Rdest, Rsrc
は、レジスタ Rsrc に入っている整数の絶対値を Rdest に入れる働きを持つ。 (abs は、absolute value (絶対値)に由来する。)
これは3つの命令の列に置き換わる。 例えば、
abs $8, $9
であれば、
addu $8, $0, $9 # $8 <- 0 + $9 つまり、$8 <- $9
bgez $9 8 # $9 >= 0 なら 8 バイト先へ分岐(つまり、次の命令を飛ばす)
sub $8, $0, $9 # $8 <- 0 - $9 つまり、$8 <- -$9
に置き換わる。bgez 命令の名は branch on greater than equal zero に由来する。
ラベルを使うなら、
addu $8, $0, $9 # $8 <- 0 + $9 つまり、$8 <- $9
bgez $9, L # $9 >= 0 ならラベル L へ分岐(つまり、次の命令を飛ばす)
sub $8, $0, $9 # $8 <- 0 - $9 つまり、$8 <- -$9
L:
のようになる。
疑似命令のように 1 つの命令が複数の命令に置き換わるしかけは便利なので、 そのような命令をユーザが自分で定義できるようにしてあるアセンブラも多い。 そのようにしてユーザによって定義された命令をマクロ命令と言う。 マクロ命令を定義できるようなアセンブラをマクロアセンブラと言う。 マクロ命令を実際のアセンブラ命令に置き換えることをマクロの展開という。
マクロアセンブラは確かに便利である。 しかし、UNIX のようなシステムでは、あえてマクロアセンブラを用意しないことがある。 何故かというと、
そういうわけで、もし、自分が使っているシステムにマクロアセンブラがなくても、 がっかりしなくてよい。
$8 と $9 の和を $10 に入れるだけのプログラムを書いてみる。 和は、符号なし整数の和とする。
適当な名前のファイルにプログラムを書く。ここでは、addu.s としておく。 Unix では、アセンブリ言語プログラムファイルの拡張子は .s である。
addu.s の内容:
.globl main
main: addu $10, $8, $9
1行目の .globl main は、main がグローバルなラベルであることを示す。 グローバルなラベルは、他のファイルからも参照できる名前になる。 (もっと正確に言えば、アセンブリ後のファイルの外から、名前が見える。) C 言語で言えば、外部リンケージを持つ名前である。 他のファイル内のルーチンから呼ばれる可能性のあるルーチンについては、 開始番地にグローバルなラベルをつけないといけない。 main もそれと同じ扱い。
1行目の .globl の前には、タブ文字が入っていて、それによってプログラム の字下げをしている。アセンブリ言語の命令はこのようにタブ文字で字下げしておく。
注意!: .globl のつづりに注意しましょう。.global ではありません。
グローバルでないラベルについては、 複数のファイルで同じラベルを使ってもよいので、 ラベル名がかち合わないかという心配をしなくてよい。 グローバルなラベルについては、かち合わないようにしないと、 例えばどのファイルのルーチンを呼び出しているのかわからなくなる。 (file1 にも file2 にも foo というグローバルなラベルがあったとして、 file3 で 「foo から始まるルーチンを呼び出す」という処理を指示していたら、 果たして file1 の foo が呼ばれるべきなのか、 それとも file2 の foo が呼ばれるべきなのか、わからなくなる。) このような事情があるので、グローバルなラベルは使い過ぎないよ うにしたほうが良い。
2行目は、メインルーチンの始まりなので、main というラベルを貼ってある。 メインルーチンには必ずこの名前をつけないといけない。 (C で処理が必ず main 関数から始まるのと同じ。) ラベルの直後に必ずコロン(:)を書くこと。 このとき、ラベルは字下げせず、行の先頭から書く。
アセンブリ命令 addu $10, $8, $9 は、$8 と $9 の和を $10 に入れる。 この部分はタブ文字で字下げしておく。 つまり、main: というラベルと addu というニーモニックの間にタブ文字を入れておく。
基本的な規則として、ラベルを貼るときは行の先頭からラベルを書くが、命令はタブで字下げして書くようになっている。
コマンドラインから
% xspim &
で、xspim を起動する。
|
|
| xspim を起動したところ |
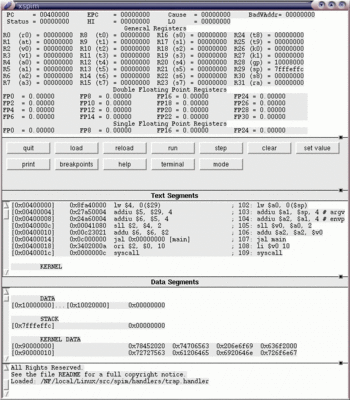
xspim は MIPS CPU のシミュレータである。 xspim は、アセンブルの処理と、 その後の機械語の実行の処理(実際には実行のシミュレーション)の両方をやってくれる。
load ボタンを押してファイル名として addu.s を指定。 assembly file ボタンをクリックする(か、あるいはリターンキーを押す)と、 ファイルが読み込まれて、機械語に変換される。 [addu.s のダウンロード]
ただし、xspim を起動した時のカレントディレクトリに addu.s がないと読み込めずにエラーになる。 他のディレクトリに置いてあるなら、 例えば、kiso/addu.s のようにファイル名を指定する。
Text Segments と書かれたウィンドウに、変換後の機械語が表示される。 プログラムは 0x00400000 番地から始まる約束である。(MIPS 固有の約束。) 0x00400020 よりも前に書かれているのは、 メインルーチンを呼び出すための準備を行なうルーチンで、 アセンブラが自動的につけ加えたものである。 (この部分の説明は今はしない。余裕があればあとで説明する。) 0x00400020 以降がユーザの書いたプログラムのアセンブルの結果である。 ここではもちろん1行しかなく、
[0x00400020] 0x01095021 addu $10, $8, $9 ; 2: addu $10, $8, $9
のように表示されている。 この行において、
xspim のウィンドウの一番左上には、PC (プログラムカウンタ)の内容が表 示されている。EPC, Cause, BadVAddr, Status については、 とりあえず気にしないでよい。 その後には、HI レジスタ、LO レジスタの値が表示されている。 表示は16進数で行なわれる。
その下に、General Registers と書かれた区域があり、そこに、汎用レジス タの値が表示されている。
さらにその下に、浮動小数点レジスタの値が表示される。 倍精度を入れる場合は、 レジスタを2個組にして使うので、組にしたものを1つとして、表示している。 単精度浮動小数点レジスタとして見た場合の表示は、下にあるが、 最初は全体が見えないので、適当に、ウィンドウのサイズを変更して見る。 (xspim ウィンドウの右はし近くにある灰色の小さな四角を、 左ボタンでつかんで上下にドラッグする。)
最初、$8〜$10 には 0 が入っているので、 このプログラムを実行しても本当に和の計算がされたかどうかわからない。 そこで、xspim の機能を使って、 レジスタに値をセットしてみる。 (この機能は、プログラムのテストのために用意されている)。 $8 に 1 を、$9 に 2 をセットしてみよう。set value ボタンをおして、 register/location の欄に 8 を、value 欄に 1 を入力する。 set ボタンを押せば、セットが行なわれ、8番レジスタに1が入る。 セット操作をやめる場合は abort command ボタンを押す。 同様にして $9 に 2 をセットする。
プログラムの実行は、一気に最後まで行なうことも、1ステップずつ行なう こともできる。(1ステップでなく、n ステップずつというのも可能。) ここでは、プログラム実行の様子を見るために 1ステップずつ実行してみる。 step ボタンを押すと、設定のためのウィンドウが出るが、 "number of steps" 欄にはステップ数1がすでに設定されているので、 設定の変更は必要ない。 args 欄はとりあえず気にしなくてよい。step ボタンをクリックするたびに、 1ステップずつ実行が進む。 0x00400020 番地まで実行が進むと、$10 に計算結果 3 が入っているのが確認 できる。
ステップ実行でなく、一気に最後まで実行したければ、run ボタンをクリック して、出たウィンドウの ok ボタンをクリックすればよい。
xspim を終了させるには、quit ボタンをクリックする。確認のためのウィン ドウが出るので、本当に終了したければ、quit ボタンをクリックする。
次の2行を入れたファイル abs.s を作ってアセンブルしてみると、abs $8, $9 が3つの命令にアセンブルされるところが見られる。[abs.s のダウンロード]
.globl main
main: abs $8, $9
以前に load したプログラムが xspim の中に残っている場合は、 clear ボタンをクリックして、出たメニューの中から、 ドラッグにより、「memory & registers」を選ぶと、まっさらになる。