|
| MIPS R2000 プロセッサの構造 |
以下では、機械語がどのようにできていて、それらをどのように組合せてプ ログラムが作られるかを説明したいのだが、機械語は、CPU ごとに大きく異なっ ている。従って、特定の CPU の機械語を説明してもその説明が他の CPU にも あてはまるわけではない。
しかし、それを承知の上で、ここでは MIPS という特定のプロセッサの機械 語を説明しようと思う。というのは、具体例で説明されなければ、機械語がど んなものかを理解するのは難しいからである。また、機械語が各プロセッサに よって違うと言っても、1つのプロセッサの機械語を理解すれば、他のプロセッ サの機械語を理解するのもやさしくなる。機械語設計の考え方は共通する部分 が多いからである。
MIPS は SGI 社のコンピュータ、ソニーが昔出していたワークステーション、ソニーのプレイステーションなどに使われている CPU である。携帯情報端末などにもよく使われている。プリンタの中にもよく入っている(印刷機構の制御、PostScriptなどのページ記述言語の処理などを実行)。
※プレイステーションの CPU は、MIPS R3000 という CPU をベースにしたカ スタム CPU (特注品)である。 ただし、プレイステーション3 では Cell という名前の全く異なる設計の CPU が使われている。
コンピュータ科学科にも、SGI の O2 というワークステーションがある。コ ンピュータグラフィクス関係の分野で SGI のマシンはよく使われている。 (しかし、SGI のマシンも最近は Intel 系 CPU だったりするが…。)
MIPS CPU は設計に無駄が少なく、理解しやすいと言われており、よく欧米 の授業の題材になっている。
※逆に、Intel Pentium シリーズなどは、やたらに複雑で大きく、命令セッ トもごちゃごちゃして汚いと言われている。(複雑なために消費電力も大 きい。)
MIPS は Microprocessor In PlayStation の略である(というのは冗談であ る)。
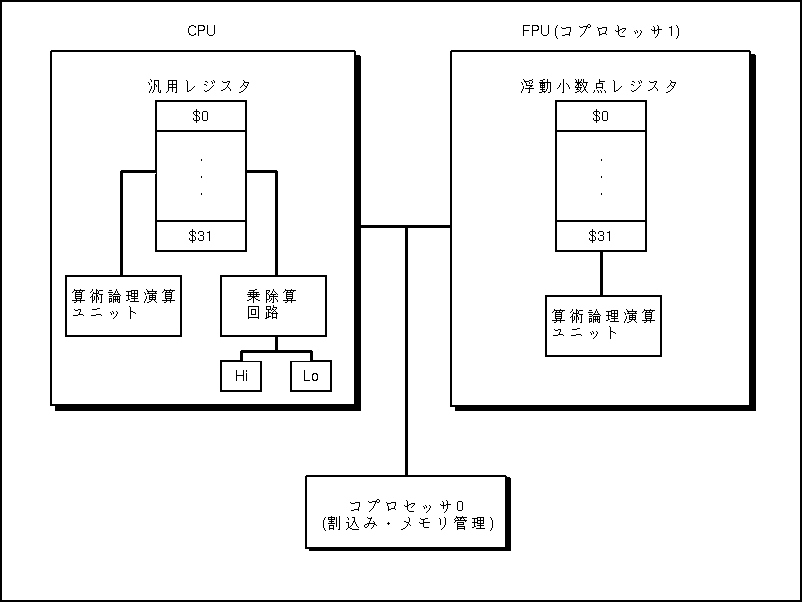
MIPS の構造の概略は下図の通りである。
|
|
| MIPS R2000 プロセッサの構造 |
以下の説明で単に「図」と言えば、この概略図を意味する。 正確には、これは MIPS シリーズの CPU のうち、 R2000 という型番のものだが、その後の R3000 なども基本的な設計は変わら ない。R2000 の場合、FPU が コプロセッサになっている。
※ 図にはもう一個 "コプロセッサ" と書かれたコプロセッサがあるが、これ については、当面説明しないので気にしないでよい。
CPU には汎用のレジスタが32個ある。汎用という意味は、あとでわかる。こ れらに0から31までの番号がついている。0番のレジスタは $0、1番のレジスタ は $1 などと書き表す約束である。レジスタのサイズは全部 32 ビット(つま り4バイト)である。MIPS では 1 ワードは32ビット(4バイト)である。 (実は、その後1ワードが64ビットの MIPS も作られているが、この授業では取 りあげない。)
FPU もレジスタを32個持っている。やはりサイズは1個あたり32ビットであ る。従って、FPU のレジスタ1個には単精度浮動小数点数1個が入れられる。 倍精度浮動小数点数は64ビットあるから、レジスタに入れたい場合には、レ ジスタを2個用いる。この場合、$0 と $1を組にし、$2と$3を組にし、という ようにして使う。
CPU のレジスタとコプロセッサのレジスタの間で、データの受け渡しをする ための命令が用意されている。浮動小数点演算をする場合は、CPU レジスタか らFPU レジスタにデータを転送し、FPU 上で演算を行なってから、その結果を FPU レジスタから CPU レジスタへ転送する、といった処理をする。
演算はすべてレジスタを対象として行なう。例えば、加算命令に4種類ある が、その1つは
add Rd, Rs, Rt
という一般形をしており、
Rs と Rt の内容の和を Rd に格納する
という意味であるが、Rs, Rt, Rd はどれも32個の CPU レジスタのうちの1つ である。 例えば、Rs が $8(8番レジスタ), Rt が $9, Rd が $10とすると、
add $10, $8, $9
となる。
レジスタ Rs, Rt, Rd の代りにメモリの番地を指定することはできない。それ が「すべてレジスタを対象として行なう」と言った意味である。メインメモリ にアクセスすると遅くなるので演算の時にはメモリにアクセスしないという方 針で設計されているのである。レジスタはメインメモリよりもずっと速く動作 することを思い出してほしい。
乗算に関しては、特別な事情が生ずる。32ビットの整数どうしをかけ合わせ ると、結果を格納するのには64ビット必要である。そこで、hi レジスタと lo レジスタという特別なレジスタが用意されており、乗算結果の上半分の32ビッ トが hi に、下半分の32ビットが lo に格納されることになっている。 除算についても似た事情が生ずる。除算では商と剰余(余り)が出るからであ る。そこで、商を lo に、剰余を hi に入れるようになっている。
図中 CPU の Arithmetic Unit と書かれた部分が乗除算以外の整数演算と論 理演算を受け持っており、Multiply Divide と書かれた部分が乗除算を受け持っ ている回路である。図中の FPU の Arithmetic Unit は浮動小数点演算の全て を受け持っている。
32個の CPU レジスタのうち、$0 だけは少し特殊で、その値が常に0に固定 されている。$0 の内容を読み出すと、常に 0 が読み出されるし、$0 に何か を書き込もうとしても、$0 の内容は 0 のままで変わらない。このようなレジ スタがどのように役立つかはあとでわかる。
先程言ったように、演算はレジスタに対してだけ行なわれるので、メモリの 内容に対して演算をしたければ、一旦メモリの内容をレジスタにコピーし、そ れに対して演算を施してから、その結果を(必要なら)メモリに書き込まなけれ ばならない。
MIPS のように、演算はレジスタ間だけで行ない、メモリに対する演算は上 のようにしてロード・ストア命令を利用して行なうようなコンピュータアーキ テクチャを「ロード・ストア・アーキテクチャ」と言っている。 ※ 「アーキテクチャ」というのは、まあ、「設計方式」というような意味です。
前に説明したように、昔のコンピュータでは、演算用に使えるレジスタを多数 作るのが難しかった(アキュムレータの話を参照)ので、ロード・ストア・アー キテクチャは採用しにくかった。しかし、今ではごく普通の設計になっている。
機械語命令は適当な長さ(ビット数)の2進数で表される。一般論としては、 命令の種類ごとにその長さは違っていてもよい。命令の長さ(ビット数)を命令長と言っている。「これこれの命令は16ビット長である」といった言い方もする。命令長は8ビットの倍数になっているマシンが大半である。
MIPS の機械語は、どれも32ビット長である。命令長を統一することで設計 が単純化され、それが高速化につながるという考え方である。 (ちなみに、Pentium 系の CPU では、命令長が命令ごとに大きく違っている。)
[春学期の復習] CPU は命令を実行する際、
機械語を設計する際、デコード処理が簡単になるようにしたほうがよい。 MIPS では、命令語の32ビットのうち、最上位の6ビットを見ると命令の大まか な分類ができるようになっている。それによって分類したあとで、場合によっ ては、残りの26ビットのうちの何ビットかを使って命令を特定するようになっ ている。
例えば、加算命令 add Rd, Rs, Rt の場合、最上位6ビットは0である(0 を6 ビットで表したもの 000000 が入っている)。これだけでは他のいくつかの演 算(例えば減算 sub)と区別ができないのだが、最下位の6ビットに 0x20 が入っ ているのを見ると、add 命令だとわかる仕掛けである。減算 sub なら最下位6 ビットは0x22なので、区別がつく。
add Rd, Rs, Rt 命令の Rd, Rs, Rt を指定するにはどうするか? これらは レジスタの指定であり、レジスタは32個ある。32 は2の5乗だから、5ビットあ れば、全部のレジスタを区別できる。そこで、Rd, Rs, Rt をそれぞれ指定す るのにそれぞれ5ビット使うことにする。それで、add 命令は次のような構造 をしている:
┌────┬────┬────┬────┬────┬────┐
│ 0 │ Rs │ Rt │ Rd │ 0 │ 0x20 │
└────┴────┴────┴────┴────┴────┘
6 5 5 5 5 6 ←各フィールドの
ビット数
この図で Rs と書いた所は、レジスタ Rs の番号を5ビットで表したものであ る。例えば、Rs として $3 を指定するなら、00011 (2進数の3)である。Rt, Rd についても同様である。 先程の add $10, $8, $9 を例にとると、Rs, Rt, Rd が $8, $9, $10 で 8 = 01000(2進), 9 = 01001(2進), 10 = 01010(2進)であるから、
┌────┬────┬────┬────┬────┬────┐
│ 000000 │ 01000 │ 01001 │ 01010 │ 00000 │ 100000 │(← 2進)
└────┴────┴────┴────┴────┴────┘
6 5 5 5 5 6
と表されることになる。
このように命令語32ビットを上から 6,5,5,5,5,6ビットに分けた形式の命令が MIPS にはたくさんあり、この形式を R 形式(R の文字は Register から来て いる)と言っている。
なお、上図 の Rd フィールドの右どなりの5ビットのフィールドは、add 命令 では利用されておらず、単に 0 が入っている。(このフィールドは、シフト命 令という命令で使われる。)
他の命令の例として、無条件分岐命令 j (jump)を取る。j は下のような形式 になっている。
┌────┬────────────────────┐
│ 2 │ Target │
└────┴────────────────────┘
6 26
最上位6ビットに2が書かれているのを見ると、無条件分岐命令だとわかるよう になっている。残りの26ビットは Target フィールドというもので、Target フィールドにアドレスを指定すると、そのアドレスに無条件で分岐(ジャンプ) する命令になる。 MIPS では、このように32ビットを上から6ビット、26ビットに分けた命令形 式を J 形式と呼んでいる。
命令の形式としては、上記 R 形式と J 形式以外には、もう一つ I 形式と いうものしかない。(MIPS はこのようにずいぶん単純であるが、Pentium など だと、もっと多種類の形式を持っている。)
I 形式の例としてロード命令をとる。メモリから 1 ワード(32ビット)のデー タをレジスタに転送する命令 lw (load word)は次の形式である:
┌────┬────┬────┬────────────┐
│ 0x23 │ Rs │ Rt │ Offset │
└────┴────┴────┴────────────┘
6 5 5 16
最上位の 0x23 を見ると、lw 命令とわかるようになっている。この命令は、 レジスタRsに入っている値 + Offset部の値 で計算されるアドレスにある 1 ワードのデータをレジスタ Rt に転送(コピー) する。
例えば、
┌────┬────┬────┬────────────┐
│ 0x23 │ 0x08 │ 0x09 │ 0x04 │
└────┴────┴────┴────────────┘
6 5 5 16
という命令であれば、Rsフィールドの値 が 8 なので、8番レジスタに入って いる値と Offset 部に入っている値 0x04 との和がまず計算される。今仮に8 番レジスタに10000(10進)という値が入っていたとすると、Offset 部の値 4 と合計して10004 という値が得られる。従って、この命令の実行により、 10004番地から始まる1ワードのデータが読み取られ、(Rtで示される)9 番レジ スタに入れられる。
┌────┬────┬────┬────────────┐
│ 0x23 │ 0x08 │ 0x09 │ 0x04 │ (命令)
└────┴────┴────┴────────────┘
│ │
│ │
↓ $8 $9 ↓
─┬──────┬──────┬─ │
レジスタ群 → …│ 10000 │ X ←─ │ ←───┼───┐
─┴──────┴──────┴─ │ │
│ ↓ │
│ 10000 4 │ │
└──────→ + ←─────┘ │
│ │
│ 10004 │
↓ │
─┬──────┬─ │
メモリ → …│ X ─→ │───→───┘
─┴──────┴─
10004番地
この Offset フィールドに入れられた数値のように、命令語の中に直接埋め込 まれた数値を即値(immediate value)と呼んでいる。(メモリやレジスタから取ってこなくても命令自身の中を見れば即座にわかる数値だから即値と言う。) 即値は、命令に直接埋め込まれているので、いつその命令を実行しても、毎回 同じ値である。それに対して、例えば、add Rd, Rs, Rt 命令の実行では、Rs の値が使われるが、それは命令実行の時点でレジスタに入っている値だから、 同じ命令であってもその値は毎回実行のたびに異なる。
※ 即値という言葉は、MIPS に限らず、一般的に使われる用語なので、覚えて おきましょう。
一般にメモリにアクセスする必要のある命令では、アドレスを何らかの方法 で指定しなければならない。アドレス指定のことをアドレッシングと言うが、 その方式には色々な考え方があり、昔から様々なプロセッサで様々なアドレッ シングの方式が使われてきた。そのような色々な指定方式の1つ1つをアドレッ シング・モードと呼んでいる。過去には1つのプロセッサに非常に豊富なアド レッシングモードを持たせることが盛んに行なわれた。しかし、最近のプロセッ サはアドレッシングモードとして単純なものだけを用意するものが多い。MIPS の場合、上のロード命令で示したような、「レジスタの値 + 即値」によるア ドレッシングしか用意していない。(これだけあれば十分である。)
機械語命令は上のように無味乾燥な2進数で表されており、普通の人間には とても記憶できるものではない。記憶しなくても機械語表を見ながら使うのは 可能ではあるが、相当な忍耐力を要するだろう。そこで、実際には各命令に対 して、人間が見やすく読みやすく憶えやすい表記法を与えてあり、それを書き 並べることでプログラミングできるようにしてある。すでに出てきた add Rd, Rs, Rt というのが実はその表記法による命令表現の1例である。この表記の add のよ うに、命令に対してそれを表す覚えやすい名前を与えたものをその命令の「 ニーモニック(mnemonic)」と言う。
この記法は一種のプログラミング言語と考えられるので、アセンブリ (assembly)言語と呼ぶ。アセンブリ言語で書かれたプログラムを機械語へと変 換してくれるソフトウェアをアセンブラ(assembler)と言う。そのような変換 をすることをアセンブルする、と言う。(アセンブラが行う処理のことも「ア センブルする」と言うし、ユーザがアセンブラを使ってそのような変換をする ことも「アセンブルする」という。)
我々が C のような言語でプログラムを書いた時、コンパイラはそれをアセ ンブリ言語のプログラムに翻訳する。この過程を「コンパイル」といい、コン パイルを行うことを「コンパイルする」という。 コンパイルの結果得られたアセンブリ言語のコードをアセンブラにかければ、 機械語のプログラムを得ることができる。
※「コード」というのは「プログラム」の別の呼び名です。「アセンブリ言語のコード」というのは長いので、「アセンブリコード」とか「アセンブラコード」ということがあります。
あるいは、コンパイラがアセンブリ言語を経由せず、いきなり機械語を吐き 出すこともある。多くのコンパイラでは、機械語を直接吐くか、一旦アセンブ リ言語プログラムを吐くようにするか、動作を切り換えられるようになってい る。(しかし実は、機械語を直接吐いているように見えるコンパイラも、ユー ザのあまり気付かないような「裏」の処理でアセンブラを使っている事がある。 つまり、一旦アセンブリコードを吐き出して、それをすぐにアセンブラにかけ ているわけである。) コンパイルの対象になるプログラミング言語をそのコンパイラのソース言語 (source language)と言い、コンパイラが出力するプログラムの記述言語をそ のコンパイラのターゲット言語(target language)と言う。上で述べたように、 通常コンパイラのターゲット言語はアセンブリ言語か機械語である(そうでな い例は時間が許せば後程説明する)。 例えば、C 言語のコンパイラであれば、ソース言語は C 言語であって、(普通) ターゲット言語はアセンブリ言語か機械語である。
プログラミング言語どうしの比較において、高水準言語と低水準言語、または高級言語と低級言語という区別がよくされている。
コンパイラは一般に、高水準言語のプログラムを、それよりも低水準な言語 のプログラムに変換する。
※注意: 高水準(高級)というのは、(低水準あるいは低級言語より)「出来がよい」と いうことを意味しません。しかし、同じようなことをプログラムするのに、一 般に高水準言語で書くほうが簡単に(短く)書けます。
ここまでで、アセンブラが機械語を生成すると説明したが、実はもう少し詳しく言うと、アセンブラが生成したものがそのままプログラムとして実行されるわけではない。アセンブラが生成するファイルはオブジェクトファイルと呼ばれるが、実行可能プログラムを作り出すには、さらにオブジェクトファイルをリンカと呼ばれるプログラムにかけてやらなければならない。
リンカが必要となる理由は、一般にプログラムがいくつかの部分に分けて作 られるために、複数のオブジェクトファイルを結合しなければ正しく動作する 機械語プログラムができないからである。この結合処理をリンクという。リン ク処理を行なってくれるソフトウェアをリンカという。
cc や gcc は、普通自動的にリンカを呼び出してくれるので、学生諸君はこ れまでリンカの存在をあまり意識しなかったかも知れない。
プログラムがいくつかの部分から作られる理由のいくつかを挙げよう:
C 言語でプログラムを書く時、sqrt とか sin, cos のような関数を使って いる時にはコンパイル時に -lm オプションが必要であることは知っている だろう。これは、libm と呼ばれるライブラリの中から必要なルーチンを探 してリンクするように指示しているのである(「ライブラリを include する」 という)。
※ libm は数学関数ライブラリと呼ばれるものです。(m は mathematics の m)
UNIX には libm 以外にも色々なライブラリが用意されており、みな lib×× という形の名前になっている。 その中のルーチンをリンクする時(= lib×× を include する時)には -l×× というオプションを使う。
自動的に libm の中のルーチンを探すようになっていれば -lm オプション が不要になるのに、と思うかも知れないが、例えば libm の中の sin ルー チンが気に要らないので自分で作ったライブラリの中の sin ルーチンを使 いたい、という場合もあるだろう。そのような場合、勝手に libm を include されては迷惑である。(ただし、最も基本的なライブラリについては、 -l オプションで指定しなくても良いことになっている。libc ライブラリが そう。)
┌────────────┐
高水準言語 │ ↓
プログラム --→ コンパイラ --→ アセンブラ --→ リンカ --→ コンピュータ
↑ で実行
アセンブリ言語 │
プログラム ------------------┘